
technology


Hello. I am in charge of Cinnamon AI public relations.
Cinnamon AI develops products using natural language processing technology. Aurora Clipper(Aurora Clipper) provides services such as obtaining dates with specific context (event dates, contract dates, etc.) and person names (relationships between contract parties), extracting key points from long texts, and classifying text. This product is used for various purposes.
Cinnamon AI has approximately 100 AI researchers globally, and among them, a team specializing in natural language processing is constantly improving the AI model that forms the basis of Aurora Clipper.
In this article, we will discuss the research results related to natural language processing that Cinnamon AI has been working on so far at the A-rank conference.CIKM 2020Fujii, delivery manager of Cinnamon AI, will introduce the outline.
Hello. This is Fujii from Cinnamon AI.
This timeAurora ClipperI would like to introduce information extraction, which is one of its functions.
The information extraction function automatically extracts necessary parts from various documents. It is possible to extract and summarize confirmation items in contracts and reports,Toshiba Energy Systems CorporationIt is used by many customers including Mr.
Now, in general, when building an algorithm for information extraction, a lot of data is required. This is because context is used to extract only items with a specific role from among items of the same type. For example, if you want to extract the event date from a document about an event, you can only extract the event date from other date items by using the context of that item.
As a dataset more commonly used in actual information extraction research.CoNLLHowever, this dataset uses 15,000 data as training data.
However, when actually building an information extraction algorithm for business, it is not realistic in terms of cost or time to collect 15,000 pieces of data. Most of the Aurora Clipper implementation projects carried out by Cinnamon AI have approximately 50 to 300 pieces of training data.
Even when algorithms yield good results as research results, in most cases the premise is that they are the result of learning using large amounts of data. As a result, academic research results require a significant amount of time and cost before they can be translated into business.
Furthermore, most of the research data is written in English, and even if the latest algorithms are proposed, it takes a lot of time to localize them into Japanese, so information extraction in Japanese is currently lagging behind worldwide. (The idea of localizing the latest algorithm to Japanese ishere).
Based on our experience in introducing Aurora Clipper to many companies, Cinnamon AI has been researching and developing algorithms to achieve high accuracy with small amounts of data and Japanese data.
And the result is CIKM 2020”AURORA: An Information Extraction System of Domain-specific Business Documents with Limited Data“My paper has been accepted, so I would like to introduce it to you!
Summary①
✔ Generally, a large amount of data (approximately 15,000 items) is required to build an information extraction algorithm.
✔ On the other hand, it is not realistic to prepare large amounts of data for business use.
✔ Aurora Clipper has independently developed an algorithm that achieves high accuracy with a small amount of data.
The overall image of the AURORA algorithm built with Cinnamon AI is shown in the figure below.
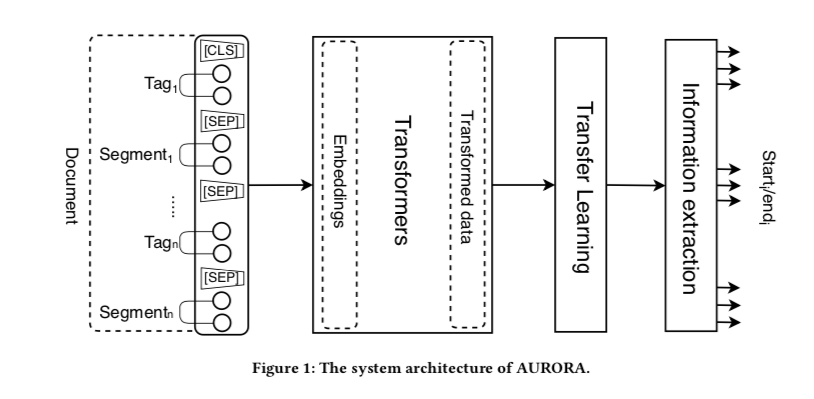
AURORA first receives an input document containing TAG and SEGMENT.
TAG and SEGMENT correspond to the extraction target item and its value.
For example, when extracting the contract date from the contract, TAG would be "contract date" and SEGMENT would be "2020/08/24".
This TAG and SEGMENT pair is supplied to the Transformer layer, where it is converted and passed to the hidden layer.
After that, transfer learning is performed using a layer composed of CNNs to remove unnecessary information, and finally the items to be extracted are inferred using an information extraction model that uses a Question-Answering task.
A major feature is that it is structured so that multiple algorithms can be selected to be applied to the Transformer layer.
Therefore, not only BERTELECTRAVarious algorithms such as RoBERTA and RoBERTA can be applied to the Transformer layer.
In addition, by performing transfer learning using the representations obtained from these Transformer layers, it is possible to simultaneously extract a large number of types of items with high accuracy from a small amount of data.
The actual experimental results are as follows.
We used Bidding docs (77 training items, 22 testing items) and Sales docs (300 training items, 150 testing items), which are research data in Cinnamon AI.
These data are written in Japanese and are used for information extraction tasks.
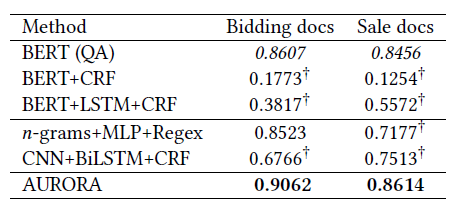
As a result, as shown in the table above, the AURORA model achieved the highest score in terms of F value, which is an accuracy evaluation index, for both Bidding docs and Sale docs.
The BERT (QA) model used as a control experiment has been applied to many natural language processing products in Japan, but it had the drawback of requiring a large amount of data for actual business use.
In this research, by using the AURORA model, we were able to achieve high accuracy even with a small amount of data.
In the future, we will further improve the pre-learning part of the Transformer layer, make it industry-specific, and incorporate it into the AURORA model to advance our research so that we can quickly provide high-accuracy models even for niche operations.
Summary ②
✔ Proposes the AURORA model that achieves high accuracy with a small amount of data by using transfer learning
✔ The AURORA model achieves higher accuracy than the conventional BERT model under the condition of a small amount of data.
✔ In the future, we plan to embed industry knowledge into the AURORA model and build industry-specific models.
For inquiries regarding this article or requests for business negotiations, please contactherePlease contact us from.
In addition, Cinnamon AI regularly holds seminars.
herePlease feel free to apply.

