
技術
第1回でSuper RAGの全体像と差別化ポイントを、第2回・第3回でAPIの組み込みパターンと機能カタログをご紹介してきました。ここまでは「どう使うか」の地図を渡す回でした。今回からは視点を変えて、Super RAGの中で何が起きているか——精度を生み出している“中身”の側に踏み込んでいきます。
最初に取り上げるのは、ドキュメント抽出です。RAGの仕組みは、抽出 → 索引化 → 検索 → 回答生成という階段で動きますが、その入口にあたる抽出の質が、後段の階段すべての天井を決めてしまう——これがSuper RAGの設計思想の中で、ひときわ強く打ち出されている前提です。表のセルが取りこぼされたり、図のキャプションが本文と切り離されたりすると、どれだけ高度な検索アルゴリズムと高性能な大規模言語モデルを後ろに置いても、正しい回答を得ることはできません。
本記事では、Super RAGがこの入口をどう設計しているか、特に内製の文書理解エンジン DocReader が、ファイル形式と内容の特性に応じてどう抽出を組み立てているかを解きほぐします。エンジン名は出てきますが、対象読者は非エンジニアの方を想定しているので、「なぜこの設計が効くか」の意思決定ロジックを軸に進めます。
記事末尾には、今回の持ち帰り検討材料として「自社データでの比較試行チェックリスト」をご用意しました。記事を読んで「うちのドキュメントだとどうなるか試してみたい」と思われた方は、無償・有償のトライアルでお客様の実データを流して結果を比較していただけます。記事末尾のお問い合わせフォームからお気軽にご相談ください。
本記事は第4回です。連載は、(I)なぜSuper RAG、(II)どう組み込むか、(III)中身を可視化、(IV)現場で何が起きているか、(V)導入判断、という5章構成で進めています。今回から第III章「中身を可視化」が始まり、抽出(第4回)、検索(第5回)、回答戦略(第6回)の順で、Super RAGの精度を支える3本柱を順に取り上げていきます。
第II章までで「Super RAGをどう組み込むか」の輪郭は掴んでいただけたはずですので、ここからは「組み込んだうえで、なぜ精度が出るのか」を理解いただく回に入っていきます。仕様書の代わりではなく、設計判断の地図を持ち帰っていただくのが目的です。
実際の業務ドキュメントは、形式も中身もまちまちです。テキストが綺麗に取り出せるPDFもあれば、紙からスキャンした画像PDFや、表が複雑なExcel、レイアウトの凝ったPowerPoint、CSVに書かれたFAQ集や用語集まで、いろいろな素材が同じ社内ナレッジに混在しています。
Super RAGの抽出層は、この多様性を1つの汎用エンジンで処理しきろうとはしません。代わりに、Super RAGの抽出層が、ファイル形式と中身の特性に応じてエンジンを振り分け、その中核を内製の文書理解エンジン DocReader が担う——という設計を採っています。
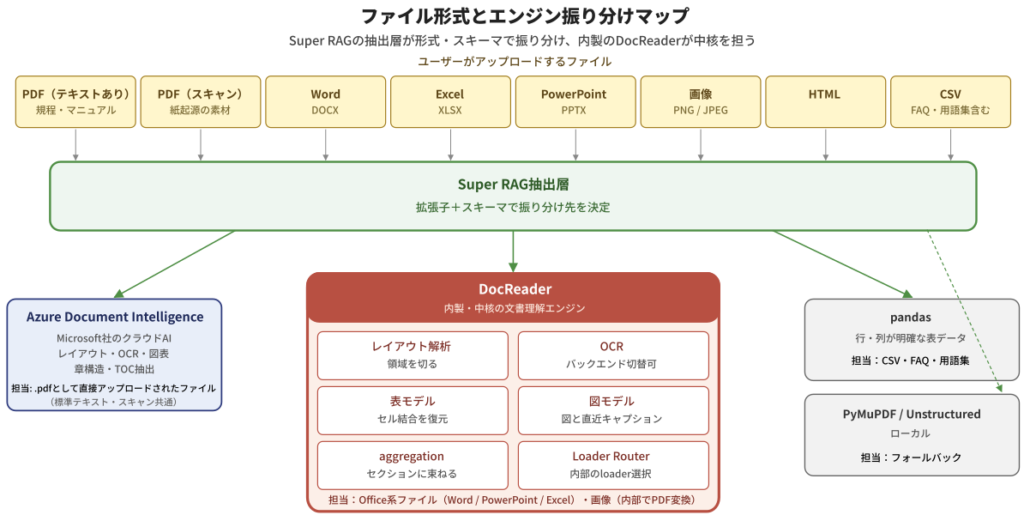
ファイル形式とエンジン振り分けマップ
DocReaderは、単独のOCRライブラリやPDFパーサではありません。レイアウト解析、OCR、表の構造復元、図の領域抽出、複数モデルの結果の統合(aggregation)——これらをまとめて1本のパイプラインに束ねた文書理解エンジンで、Word・PowerPoint・ExcelといったOffice系ファイルや、画像ファイル(PNG/JPEG)——つまり視覚情報の比重が高い/レイアウトが複雑な素材を一手に引き受けるのが、設計の中心的なポイントです(一部は Super RAG が内部でいったん PDF に変換したうえで DocReader が処理します)。
その他のファイル形式は、それぞれに合った経路を通ります。標準的なテキスト層付きのPDFは、Microsoft社のクラウド型文書解析サービス Azure Document Intelligence(以下、Azure DI)に振り分けられます。行と列が明確に決まっているCSVや、FAQ/用語集のような決まった構造を持つ表データは、pandasベースの構造化データに強い抽出器へ。検出されないファイル形式や、上記エンジンが応答できない場合のためにPyMuPDFやUnstructuredといったフォールバック用のパスも用意してあります。
ここで重要なのは、利用者から見るとファイルを投げ込むだけで適切な処理が走るという単純さです。「PDFはこっちのAPI、Excelは別のAPI、画像は画像APIへ」と利用者が振り分ける必要はありません。振り分けはSuper RAG側で済ませる——というのが設計の要点で、第3回でご紹介したドキュメント処理API(POST /api/v3.3/actions/document-extract/)も、ファイルを渡せば抽出層が中で判断する仕組みを利用者に見せています。
ここで一つ、設計上の特徴的な判断について触れておきます。エンジンの振り分けは、ファイルの中身(レイアウト)を実際に解析してから決めるのではなく、拡張子と、CSV/Excel の場合は列の構成(FAQ用なのか用語集用なのか普通の表なのか)、それに環境設定や上流の処理経路だけで決まる、決定論的な仕組みになっています。「中身を見ないと最適なエンジンを選べないのでは」と感じられるかもしれませんが、ここはトレードオフです。レイアウトを毎回解析してから振り分けようとすると、振り分けるためだけにレイアウト解析を一度走らせ、本処理で同じ解析をもう一度行う、という二重のコストが発生します。Super RAGは「毎回同じ条件なら毎回同じエンジンに振り分ける」決定論的な設計を採ることで、運用上の予測可能性と高速処理、コスト効率を優先しています。実際のレイアウト解析は、振り分けが終わったあと、それぞれのエンジンの内部——Azure DI ならクラウド側、DocReader なら 内部処理——で行われます。
このように、内製のDocReader を中核に据えつつ、必要な場面ではクラウドの強力なサービスを呼び分ける——というハイブリッドな構成が、Super RAGの抽出層の特徴です。それぞれのエンジンが得意な素材に集中することで、抽出品質と運用の柔軟性、効率を両立させています。
実務で扱うドキュメントの中心は、なんといってもPDFです。Super RAGの中で“PDF”として扱われる素材は、ユーザーが直接 .pdf としてアップロードしたファイルだけでなく、Office系ファイル(Word/PowerPoint/Excel)や画像をアップロードした際に Super RAG が内部で PDF に変換したものまで含まれます。中身も成り立ちもまちまちのこの “PDF” を、Super RAGは2系統で扱えるように設計されています。
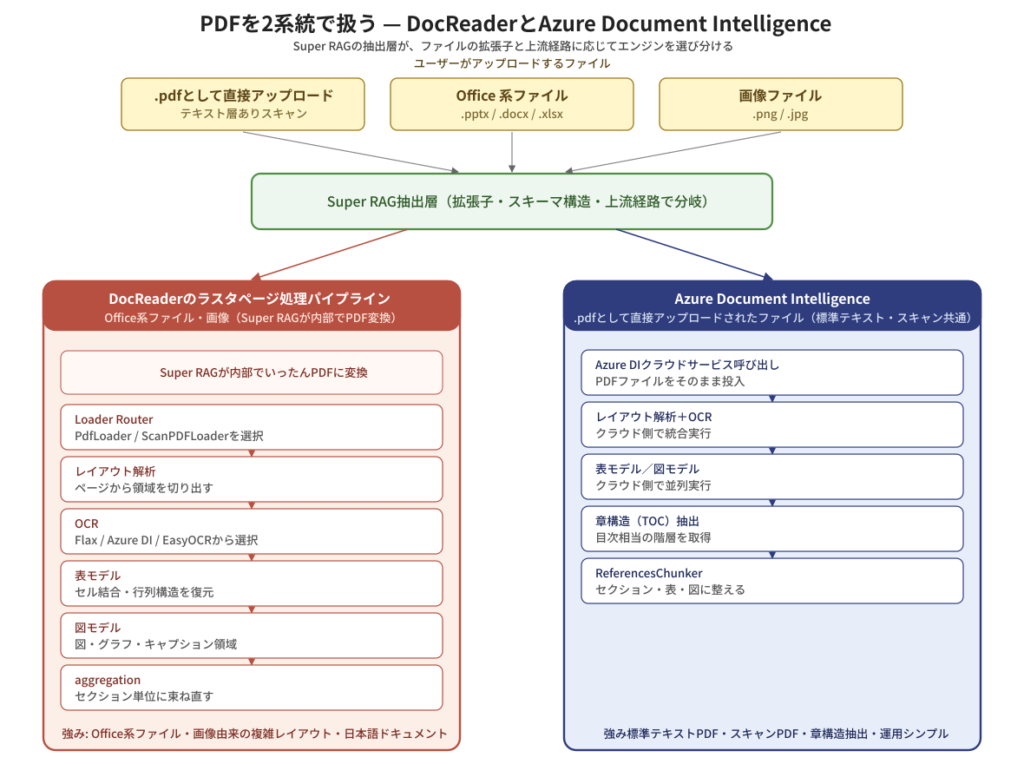
DocReader と Azure Document Intelligence の処理ステップ比較
ひとつは、DocReader のラスタページ処理パイプラインです。ページを画像として扱い、レイアウト解析→OCR→表モデル→図モデル→aggregation という多段の処理を、内製のパイプラインで動かします。Word・PowerPoint・Excel などの Office系ファイルや、画像(PNG/JPEG) ——これらを Super RAG が内部でいったん PDF に変換したもの ——を扱う系統で、視覚情報の比重が高い/レイアウトが複雑な素材で力を発揮します。
もうひとつは、Azure Document Intelligence(Azure DI)です。Microsoft社が提供するクラウド型の文書解析サービスで、レイアウト解析・OCR・表/図モデルが統合されており、章構造(目次相当)の抽出にも強みがあります。Super RAGでは、ユーザーが .pdf 拡張子で直接アップロードしたファイルは、デフォルトでこのAzure DIに振り分けられます。テキスト層が乗っている標準的なPDFも、テキスト層を持たないスキャンPDFも、.pdf で渡されればAzure DIが受け止めます。
「同じ “PDF” でも、振り分け先が違うエンジンになる」——この判断は、PDFの中身(レイアウト)を解析してから決めるのではなく、ファイルが Super RAG にどう渡ってきたかという経路と、拡張子・環境設定で決まります。たとえば、利用者が .pptx のような PowerPoint ファイルをアップロードした場合、上流の処理がそれを内部で PDF に変換しつつ「これは PPTX 由来だ」という文脈を保ったまま DocReader のラスタページ処理パイプラインに流します。一方、利用者が事前に PowerPoint を PDF に書き出して .pdf としてアップロードした場合は、Super RAG にとっては通常の .pdf ファイルが届いたのと変わらず、デフォルトで Azure DI に振り分けられます。意図はそれぞれのエンジンが得意な素材を取り違えないためで、Azure DIは文書として作られた標準PDFや章構造が明確なドキュメントに、このラスタページ処理パイプラインは Office系ファイルや画像から Super RAG が内部変換した複雑レイアウトのPDFに、それぞれの強みが出るようにあらかじめ振り分け先が決まっています。Super RAGの抽出層が入口でこの判断を引き受けることで、利用者は中身を意識せずに、安定した抽出結果を受け取れる仕組みになっています。
ここで、第1回で触れた日本語ドキュメントへの強みについて、もう少し具体的に補足します。日本語の業務ドキュメントには、縦組みと横組みが混在するページ、和文と英数字・記号が混在するテキスト、句読点や括弧の独特な記法、図表番号の「図1-2」のような複合表記など、英語前提の汎用OCRが苦手にしがちな要素が多く含まれます。DocReaderのレイアウト解析・OCRは、こうした日本語特有の素材を実務的に扱えるようチューニングされており、日本語マニュアル・規程・議事録といった「日本語+複雑レイアウト」が組み合わさる素材で効果が出やすい設計になっています。
ここまで「Super RAGの抽出層が、DocReaderを中核に据えてエンジンを使い分ける」「PDFを2系統で扱う」と見てきましたが、そもそもなぜそんな複雑な仕組みが必要なのか——という疑問もあると思います。答えは、業務ドキュメントに含まれる表と図にあります。普通のテキスト抽出だと、ここで情報がごっそり落ちてしまうのです。

通常のテキスト抽出の落とし穴とDocReaderの補い方
例えば、ある業務システムで使われている社員名簿の一部に、こんな表があったとします。
| 部署 | 社員 |
|——|——|
| 総務 | 山田 |
| | 鈴木 |
人間が見れば「鈴木さんも総務部所属」と一目で分かります。「部署」列のセルが縦に結合されていて、上の「総務」が下の「鈴木」にもかかっている、という日常的な表記です。ところが、これを単純にテキストとして取り出すと、
1 総務 山田
2 鈴木
となり、鈴木の部署が空白になってしまいます。後段のAIが「鈴木さんの部署は?」と聞かれても、「分かりません」と答えるしかありません。
DocReaderは、この種のページを画像として捉え、表モデルでセルの構造そのものを復元してから抽出します。セル結合を「結合」として認識し、列の対応関係を維持したまま下流に渡すので、AIに渡すときには「鈴木の部署 = 総務」という対応が崩れません。
もう一つの典型的な取りこぼしが、図やグラフ、フローチャート、システム構成図、組織図です。これらは見た目は分かりやすい一方で、テキストとしてはほとんど何も書かれていない(あっても断片的)ため、普通のテキスト抽出では検出すらされないことが多くあります。本文に「次の図を参照してください」と書かれていても、肝心の図そのものは抜け落ちる、というパターンです。
DocReaderは、ページ画像をまずレイアウト解析にかけて、「ここは本文」「ここは表」「ここは図」と領域ごとにラベルを付けます。図と判定された領域については、図モデルで抽出したうえで、必要に応じてLLMで内容を要約してチャンクの一部として残す——という処理が走ります。図そのものや図に直近のキャプションが、検索対象から外れずに済む仕組みです。
要するに、業務ドキュメントの中で取りこぼしが起きやすいのは、表と図——文字以外の構造を持つ部分です。素のテキスト化はこの部分を弱点として抱えており、後段の検索・回答のどこかで必ずボトルネックとして現れます。
DocReaderの設計は、この弱点を入口で押さえに行くものです。レイアウト解析で領域を切り、領域ごとに専門モデル(表モデル・図モデル・本文)で処理し、aggregation でセクション単位に束ね直す。「文字を読む」のではなく「ページを理解する」——という発想の違いが、後段の精度を底上げします。
業務で扱うドキュメントには、紙起源の素材も少なくありません。手書きを含む議事録、受注書、請求書、契約書のスキャン、行政文書のFAX原稿——こうした「ファイル形式としてはPDFや画像でも、中身はテキストとして取り出せない」素材です。
Super RAGは、こうした素材もフォルダに登録するだけで受け止められるように設計されています。スキャンPDF(.pdf 拡張子)は、標準のPDFと同じくAzure DI に振り分けられ、Azure DI 側のOCRがテキストを抽出します。PNG・JPEGなどの画像ファイルは、DocReader が内部でいったんPDFに変換したうえで、PDFと共通のラスタページ処理パイプラインに合流させ、レイアウト解析と内蔵OCRで処理します。「スキャンだから別ルート」というように利用者が振り分ける必要はなく、PDFや画像をフォルダに登録すれば、適切な経路で処理が走る——という単純さが、運用上の大きな利点です。
DocReader 内部のOCRエンジンは、将来的な環境変化に柔軟に対応できるよう、切り替えられる設計になっています。代表的な選択肢として、現在利用している自社製Flax ScannerのOCR、代替候補としてAzure DI のOCR、EasyOCR などがあり、ドキュメントの種類(印刷品質の良い文書、スキャン状態が悪い文書、手書きを含む文書など)や、精度・処理コストの要件と各モデルの性能向上に応じて、バージョンアップ時に最適なOCRを選定します。同じ DocReader のパイプラインの中で様々なチューニングの選択肢を持っていることが、精度の優位性につながっています。
抽出された内容(セクション・表・図・FAQ・用語など)は、最終工程としてチャンク化を経て、検索の単位として整えられます。ここでも、「ただ細切れにする」のではなく、素材の性質に応じて専用のチャンカーが選ばれる設計です。
主なチャンカーには、汎用の ReferencesChunker、Q&A対を1つの単位として扱う FAQChunker、用語と定義のペアを保つ DictionaryChunker、本文中心の文書を扱う FreeTextChunker、PowerPointのスライド単位を保つ PowerPointChunker、PDF添付の処理用に PDFAttachmentsChunker などがあります。「同じ抽出結果でも、チャンク化のしかたで検索精度をさらに上げる」——これがSuper RAGの特徴のひとつです。
加えて、チャンクの重なり(overlap)と窓(window)を持たせる仕組みもあります。たとえば章立ての境界をまたいで意味が続いている箇所を、隣接するチャンクに少し重ねて含めておくと、後段の検索で「境界をまたぐ質問」にも答えやすくなります。長すぎるチャンクは検索のノイズになり、短すぎるチャンクは文脈を失う——その間の最適な粒度を、コンポーネントの種類ごとに調整できる設計です。
「抽出が天井を決める」と冒頭で述べましたが、より正確に言えば、抽出 + 構造を保ったチャンク化が、後段の検索の天井を決めるのです。次回はその「検索」の中身——意味と語の両立をどう実現しているか——を扱います。
ここまで「Super RAGの抽出層がDocReaderを中核にエンジンを使い分ける」「PDFを2系統で扱う」「表・図はモデルで構造を復元する」「スキャンPDFはAzure DI、画像ファイルはDocReaderへ」と見てきました。読まれて「うちの業務ドキュメントだったらどうなるんだろう」と思われたかもしれません。
正直に言うと、ご自身のデータで試してみるのが一番速いです。Super RAGは無償・有償のトライアルをご提供しており、お客様の実データを流して実際に検索や問い合わせを行い、現状の運用と比べてどう違うかを確かめていただけます。記事末尾のお問い合わせフォームからご連絡ください。 営業より個別にご提案します。
そのときに役立つよう、社内検討で使える比較試行のチェックリストをご用意しました。「何を試すか」「どう評価するか」を整理しておくと、トライアルの精度が大きく上がります。
【持ち帰り検討材料】自社データでの比較試行チェックリスト 5つの観点で「何を試すか」「どう評価するか」を整理する。
| 観点 | やること | 成果物 | Tips |
| 1. 検証対象ファイル 形式 × 複雑度の網羅 | 形式: PDF・スキャン・DOCX・XLSX・PPTX 複雑度: 章立て/表セル/図/多段組 目安: 3〜5ファイル × 2〜3段階 | ファイル一覧 (形式 × 複雑度マトリクス) | 「既存業務、システムで苦労した文書」を含めると効果が見えやすい |
| 2. 検索クエリの設計 4タイプ × 3〜5問 | Single-hop(事実確認) Multi-hop(複数文書横断) Dictionary(用語定義)/厳密語 | 質問リスト (タイプ別タグ付き) | 業務担当者が実際に聞きたかった質問を集めると説得力が増す |
| 3. 比較観点 4軸でチェック | 抽出の正確性/検索の妥当性 回答の根拠/取りこぼし (既存RAGとSuper RAGの差を見る) | 質問×RAG×4軸の結果記録シート | 回答は「模範解答と比較してN段階評価」すると定量化できる |
| 4. 評価の指標 定量+定性 | 定量: 模範とする回答根拠の上位N件ヒット率 定性: 検証担当者による模範解答との類似性N段階評価と業務担当者の「使える」感(両輪で見ると判断しやすい) | 集計表+コメント・気づきメモ | 業務担当者に触ってもらうと合意形成が早い |
| 5. トライアル相談 個別提案 | スコープ・期間・対象ファイル数は業務要件に合わせて個別設計 (記事末尾のお問い合わせフォーム) | お問い合わせ (観点1〜4の整理を添付) | 「何を試したいか」を整理して伝えると初回設計が一気に進む |
5つの観点で、それぞれ「やること/成果物/Tips」を押さえていきます。
観点1:検証対象ファイルの選び方
形式の網羅性(PDF text-only/スキャン/DOCX/XLSX/PPTX)と、内容の複雑度(章立てが深い/表のセル結合が多い/図のキャプションが多い/多段組)を組み合わせて、3〜5ファイル × 2〜3段階の複雑度から始めるのがおすすめです。
Tips:検証の為の検証にならないよう、闇雲に複雑な文書を収集・作成せず、「既存のQ&Aシステムで苦労した文書」を含めると、効果がはっきり見えやすくなります。
観点2:検索クエリの設計
質問のタイプを4つ(事実確認の Single-hop /複数文書を跨ぐ Multi-hop /用語定義の Dictionary /型番・固有名詞の厳密語)に分け、それぞれ3〜5問ずつ用意します。
Tips:実際に業務担当者がAIに聞きたかった質問を集めると、評価の説得力が増します。
観点3:比較観点
抽出の正確性(チャンク境界・表セル・図キャプション)/検索の妥当性(上位ヒットが該当しているか)/回答の根拠(検索ヒットから実際に引用されたチャンクが妥当か)/取りこぼし(既存RAGでは出ない情報がSuper RAGで出るか)の4軸で見ます。
Tips:想定質問と模範回答、回答根拠をまとめたExcel表を作成し、既存RAGとSuper RAGの回答のどちらが理想に近いか採点することで、両方のRAGの差が明確化されます。
観点4:評価の指標
定量(回答根拠の引用率)と定性(模範解答との類似性N段階評価、業務担当者が「使える/使えない」と感じるか)の両輪で。
Tips:定性評価は、できれば業務担当者に触ってもらうと、社内の合意形成が早く進みます。
観点5:トライアルの相談
スコープ・期間・対象ファイル数といった具体設定は、業務要件によって最適な形が変わります。記事末尾のお問い合わせフォームからお気軽にご相談ください。営業よりお客様の状況に合わせてご提案します。
Tips:相談時に「観点1〜4で何を試したいか」をあらかじめ整理して伝えていただくと、初回のトライアル設計が一気にスムーズになります。
次回(第5回)は、ハイブリッド検索とリランク — 「意味」と「語」の両立をお届けします。今回は「抽出が後段の天井を決める」という話でしたが、その天井をどこまで使い切れるかを決めるのが検索です。
具体的には、「要するにどんな概念か」を問う質問に強いベクトル検索と、「型番XYZ-123」のような厳密な語に強い全文検索を、Super RAGがどう組み合わせて両方の質問タイプに対応しているか。さらに、検索結果の上位をリランクで並べ直す仕組みが、なぜ精度に効くのか。「抽出 + チャンク化」で整えた素材が、検索の段でどう活かされるかを見ていきます。
第4回(抽出)と第5回(検索)をセットで読むことで、Super RAGの前処理から検索までの一貫した品質設計の輪郭が立ち上がるはずです。
ドキュメント抽出は地味な工程に見えがちですが、RAG全体の精度の天井をここで決めてしまう重要な入口です。Super RAGの抽出層はこの入口を、内製の文書理解エンジン DocReader を中核に組み立てています。Super RAGがファイル形式に応じてエンジンを振り分け、Office系ファイル(Word/PowerPoint/Excel)と画像(PNG/JPEG)は内部で PDF に変換したうえで DocReader のラスタページ処理パイプラインが、.pdfとして直接アップロードされたファイル(標準テキスト・スキャンを含む)は Azure Document Intelligence が受け止める——という分業です。表のセル結合や図のキャプションといった、普通のテキスト抽出だと取りこぼしがちな部分も、レイアウト解析・表モデル・図モデルで構造を保ったまま下流に渡せる設計です。OCRバックエンドは、将来の市況環境の変化と技術の進化に合わせて柔軟に切り替えられます。
「自社のドキュメントだとどうなるか」が気になられた方は、記事末尾のお問い合わせフォームからお気軽にご相談ください。無償・有償のトライアルで、お客様の実データを流して結果を比較いただけます。本記事末尾の「持ち帰り検討材料」のチェックリストも、トライアル前の社内検討にお使いください。
<このシリーズの記事>

