
技術

前回までの2回で、Super RAGの全体像と、APIによる3つの組み込みパターン(①Super RAG中心/②検索特化/③前処理特化)をご紹介しました。「どこまでをSuper RAGに任せ、どこから自社で制御するか」という、いわばシナリオ軸で組み込みを眺めた回でした。
今回はそこから視点を切り替え、機能カテゴリ軸でSuper RAG APIを俯瞰します。「自社のシステムにつなぎ込む」と決めたあとで実際に開発仕様を詰めていく段階では、「結局のところAPIで何ができて、何はUIや自社運用に残るのか」という地図が必要になります。本記事は、その地図を持ち帰っていただくための辞書的な回です。 記事末尾には、今回の持ち帰り検討材料として「機能カテゴリ × 自社担当度マッピング表」を用意しました。社内の要件定義や役割分担の議論で、そのままチェックリスト的にお使いいただける形にしています。
本記事は第3回です。連載は、(I)なぜSuper RAG、(II)どう組み込むか、(III)中身を可視化、(IV)現場で何が起きているか、(V)導入判断、という5章構成で進めています。今回は第II章「どう組み込むか」の後半、機能カタログ回にあたります。第II章の前半(第2回)でパターンの選び方を見たうえで、本記事では機能の引き出しを把握する、という構造です。
なお本記事は仕様書の代わりではありません。各エンドポイントの細かなパラメータや認可仕様までは扱わず、「どんな機能カテゴリがあって、それぞれ何ができるか」を概観することを目的としています。詳細の実装に入る段階では、個々のエンドポイントが記されたAPI仕様書やチュートリアルを併読してください。
Super RAG APIは、役割の似たエンドポイントをまとめると、おおむね9つの機能カテゴリに整理できます。最初に1枚の地図でカテゴリ全体と相互関係を俯瞰しておきましょう。
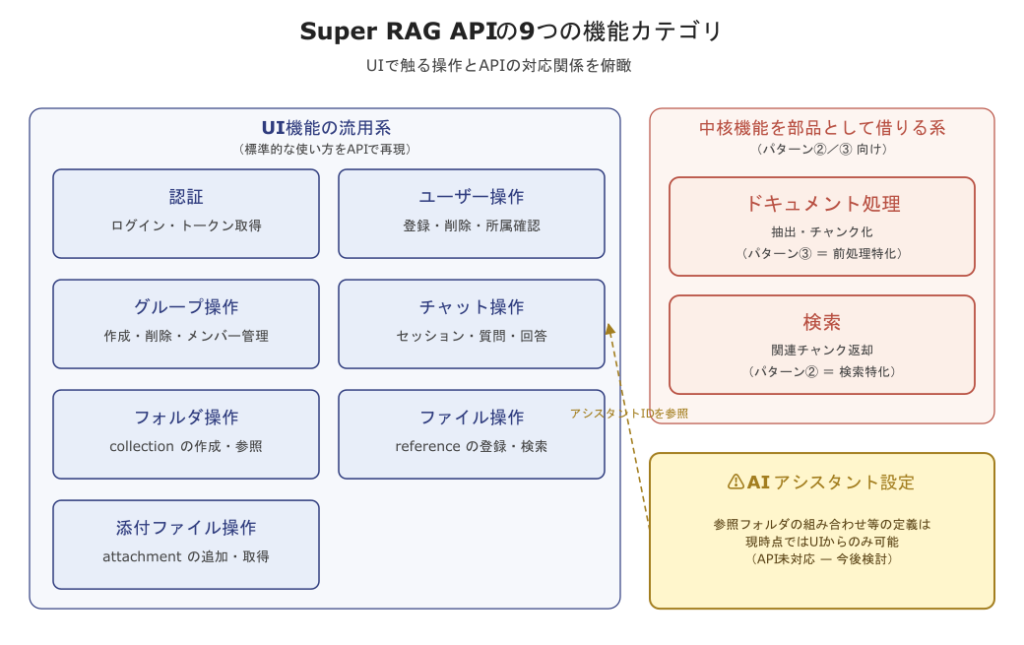
カテゴリは、UIで日常的に触る操作の単位とほぼ対応しています。ログインしてユーザーやグループを管理し、フォルダにファイルを登録して、AIアシスタント経由でチャットを行う——この一連の動きが、認証・ユーザー操作・グループ操作・フォルダ操作・ファイル操作・添付ファイル操作・チャット操作という7つのカテゴリでカバーされます。これらは、標準のSuper RAGの機能をAPIから再現したいときに使う、いわば“UI機能の流用”系のカテゴリです。
残る2つは、Super RAGの中核機能だけを部品として借りたいケース向けの拡張カテゴリです。第2回で扱ったパターン③(前処理特化)に該当する「ドキュメント処理」では、ファイルから構造化テキストを抽出してチャンクに分割するところまでをAPIで実行できます。パターン②(検索特化)に該当する「検索」では、すでに登録済みのドキュメントに対してクエリを投げ、関連チャンクをスコア付きで取得できます。回答生成のLLMやベクターDBは自社側に置いたまま、Super RAGの抽出・検索だけを差し込めるのがこの2カテゴリのポイントです。
ここで一つ注意点として、AIアシスタントの設定は、現時点ではAPIではなくUI操作でしか行えません。AIアシスタントは、参照するフォルダの組み合わせや、応答のトーンを規定する一種の“エージェント定義”にあたるもので、Super RAGのチャットはすべてこのアシスタント単位で動作します。チャットを呼び出すAPIには「アシスタントID」を渡しますが、そのIDを発行・編集する操作はUIで完結する設計です(API対応は今後検討)。
このように、API中心の運用設計を組む際には「UI側で人手が必要な機能」が存在する前提で考える必要があります。本記事ではこのような“自社で担う部分”を後の節で類型化して整理します。
ここからは、9つのカテゴリを順に見ていきます。各カテゴリで「何ができて」「API対応はどこまでで」「UI操作が必要な点はあるか」「典型的にどういう場面で使うか」を簡潔にまとめます。実装段階で改めて開く辞書として使えるように、淡々と並べる構成にしています。
なお、Super RAG APIには同じ役割のエンドポイントが複数バージョン併存している箇所があります(v3、v3.2、v3.3 など)。本記事では最新のリリース済みバージョンのみを紹介します。古いバージョンは後方互換のために残されているレガシーで、新規利用は推奨されません。
何ができるか:APIを叩く前の最初の関門にあたるカテゴリです。ID/パスワードによるログインでアクセストークンを取得し、その後のAPI呼び出しはすべてそのトークンで認証されます。多要素認証(OTP・2FA)の有効化/無効化もAPI経由で扱えます。多要素認証を無効化することで、システム的な自動処理に対応することが出来ます。
典型的な使い方:自社システムからSuper RAGを呼び出す際、サービスアカウントのトークンを起動時に取得して保持する、というのが基本パターンです。ユーザー単位でトークンを発行する設計にすれば、Super RAG側のグループ権限と自社アプリの権限を一致させた問い合わせも実現できます(後段のチャット呼び出しで参照範囲が自動的に絞られるなど)。
何ができるか:ユーザーアカウントの作成・更新・削除・検索、自分自身のプロフィール取得などが揃っています。一覧取得、IDによる単体取得、検索、所属グループの確認まで含まれます。
典型的な使い方:人事システムや社内IDマスタと連携して、入社・退職・異動に伴うユーザーメンテナンスをバッチ処理で回す、という運用が代表例です。現時点でSuper RAGはSSOに未対応ですが、これにより疑似的アカウント同期が可能となります。「リストから一人ずつ読んでAPIで登録」が基本フローのため、エラーハンドリング(既存ID・自分自身の削除不可など)の設計が運用の肝になります。詳しくは後段の「自社で担う部分」で再掲します。
何ができるか:グループの作成・更新・削除、グループ単位のユーザー一覧取得などができます。グループはSuper RAGにおける権限の単位で、フォルダもAIアシスタントもグループの中で作られます。
典型的な使い方:部門・職種・プロジェクトといった粒度でグループを切り、ユーザーと参照可能ドキュメントの範囲を統一して管理します。組織変更時のグループ統廃合と、それに伴うユーザーの再アサインがメインのオペレーションです。
何ができるか:内部呼称は「コレクション(collection)」で、ドキュメントを束ねる単位です。フォルダの作成・更新・削除、フォルダ内ファイルの一覧取得、検索などができます。
典型的な使い方:「経理規定」「製品マニュアル」「FAQ」など、用途や種類でフォルダを切り、AIアシスタントから参照する単位として使います。フォルダIDは、後述のファイル操作・チャット作成・retrieve呼び出しなど多くのAPIで必要になる中心的な識別子です。
何ができるか:内部呼称は「リファレンス(reference)」で、フォルダに登録される個々のドキュメントを指します。ファイルのアップロード、一覧取得、検索、ダウンロードができます。アップロードはフォルダ内ファイル登録のエンドポイント(POST /api/v3.2/collections/{collection_id}/references/)で行います。
典型的な使い方:日次・週次のバッチでマニュアルやFAQを更新するケースが多いカテゴリです。同一フォルダ内に同名ファイルは置けないため、更新の際は「ファイル名で検索 → 旧ファイルを削除 → 新ファイルを登録」という手順を踏みます。「古いファイルを残さず安全に入れ替える」運用は地味ですが品質に直結します。
何ができるか:チャットセッションに一時的にファイルを添付するためのカテゴリです。フォルダに登録するファイル(reference)と異なり、そのチャット内でだけ参照されるスコープのファイルを扱います。
典型的な使い方:「この申請書の内容について教えて」のように、その場限りの問い合わせに添付したいファイル(個人の計画書、特定の申請書PDFなど)に対して使います。フォルダ登録するほどではない一回限りの参照、というイメージです。
何ができるか:UIのチャット画面と同等の問い合わせを行うカテゴリです。チャットセッションの作成・更新・削除・複製、メッセージの送信が揃っています。クエリ送信のエンドポイント(POST /api/v3.2/chats/{chat_id}/messages/)からは、回答テキスト、根拠チャンク、出典情報がストリーミング配信されます。
典型的な使い方:3回シリーズで紹介してきたパターン①(Super RAG中心)の中核がこのカテゴリです。AIアシスタントID・チャットID・問い合わせ文を渡して、回答とエビデンスを受け取る——これが標準的なAPI利用の最頻パスになります。
先述のように、チャット呼び出しに必須のAIアシスタントIDは、AIアシスタント設定がUIでしか作成できないため、初回はUIで人手の準備が必要です。API呼び出しから動的にアシスタントを作る、という運用は現時点ではできません。
何ができるか:ファイルから構造化テキストを抽出する POST /api/v3.3/actions/document-extract/ と、抽出テキストを意味単位で分割する POST /api/v3.3/actions/chunking/ の2種類が中心です。さらに補助的に、テキストのベクトル化(embedding)、リランク(rerank)、プロンプト直接実行(prompt-execute)といった単発の処理もAPIで利用できます。
典型的な使い方:第2回で扱ったパターン③(前処理特化)に該当します。自社のベクターDBや検索基盤を持っていて、Super RAGからは「日本語ドキュメントを高精度に構造抽出してチャンク化する部分だけ」を借りたい、というケースで使います。チャンクをどこにどう保存するか、検索やリランクをどう走らせるかは、すべて自社側の自由度として残ります。
何ができるか:登録済みのドキュメントに対してクエリを投げ、関連チャンクをスコア付きで返却する POST /api/v3/workflows/retrieve/ が中核です。返却される各チャンクには、本文、スコア、ファイル名、メタデータなどが付与されます。
典型的な使い方:第2回で扱ったパターン②(検索特化)に該当します。Difyのようなワークフローツールやエージェント基盤からこのエンドポイントを呼び、関連チャンクを取得してから、自社LLMで回答を組み立てる構成が代表例です。検索対象のファイルIDを明示的に指定する必要があるため、事前にファイル一覧を取得して対象ファイルIDのリストを作る、という前準備が入ります。次期バージョン(Super RAG 3.4)では、Difyのネイティブ知識としてSuper RAGを扱える、External Knowledge APIでのチャンク検索にも対応します。
機能カテゴリを一通り見たところで、視点を切り替えます。「APIで何ができるか」がわかった後、実装のスコープを詰めるうえで重要なのは、API側で完結しない、自社で担う部分を見落とさないことです。
ここで言う「自社で担う部分」は3つのタイプに分かれます。タイプによって、運用設計のしどころも、PoCで検証すべき項目も異なります。
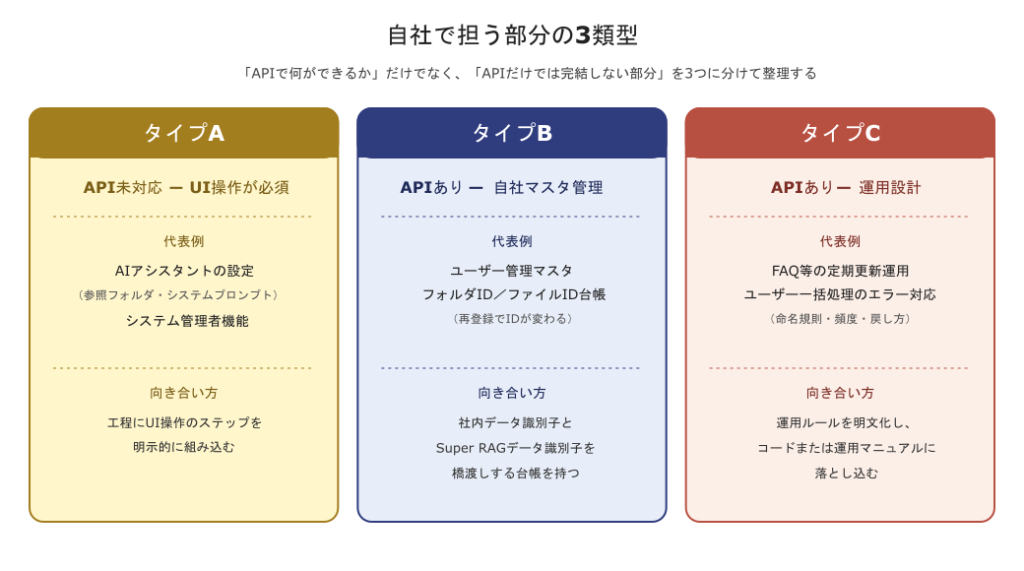
最も明確に「自社では担えない=必ずUIで人が操作する」部分です。代表例はAIアシスタントの設定で、参照フォルダの組み合わせ、応答のトーン定義、利用するLLMの選択といった項目は現時点ではAPIから作成・編集ができません。グループIDの確認も同様で、APIでも取得は可能ですが、UI上で先に作成・確認しておくほうが圧倒的に簡便です。
このタイプへの向き合い方は、シンプルです。「API中心の運用設計でも、UI操作のステップを工程の中に明示的に組み込む」ことに尽きます。初回セットアップ時のチェックリストに「UIでこのアシスタントを作成する」「UIでこのグループ名を確認してIDをメモする」といった項目を必ず入れておく、という運用が現実的です。
APIで操作はできるものの、APIだけで完結させると後で破綻しやすい部分です。代表例はユーザー管理で、Super RAG側のユーザーID・所属グループID・権限を、Excelやデータベースに自社のユーザー管理マスタとして持っておくことが推奨されます。フォルダID/ファイルIDの台帳も同じ性格です。
なぜマスタが必要かというと、Super RAGのAPIは基本的に「ID指定」で動くためです。ユーザーを登録すればユーザーIDが、ファイルを登録すればファイルIDが発行されます。再登録するとIDが変わります。次に削除や更新をかけたいときに自社側でIDがわからないと、APIが叩けません。逆に、登録時に発行IDを記録する仕組みを最初に作っておけば、後の運用は劇的に楽になります。
このタイプへの向き合い方は、「Super RAG側のIDを、自社の業務マスタに紐づけて記録するレイヤー」を最初の実装で組み込むことです。ユーザー名・メールアドレスといった「人にとって意味のある識別子」と、Super RAGが発行するUUIDを橋渡しする台帳を、Excel/DB/管理画面のどれであれ持っておく設計です。
APIは揃っており自動化も可能だが、「どう運用するか」の設計を自社側で決めなければ動かない部分です。代表例はFAQ等の定期更新ファイルの入れ替えで、技術的にはAPIで「検索→削除→登録」のループを書けますが、「どのフォルダのどのファイル名を固定にするか」「更新の頻度とトリガーは何か」「失敗したらどう戻すか」を決めるのは自社側です。ユーザー一括処理のエラーハンドリングも同じカテゴリで、既存ユーザーの重複・最後の管理者の削除不可・自分自身の削除不可といったエラー条件への分岐を自社側で実装する必要があります。
このタイプへの向き合い方は、「運用設計をプログラムや画面機能に落とし込んでシステムでコントロールする」または「運用ルールをコードの外に文書としてまとめる」ことです。配置場所・命名規則・更新頻度・エラー時の手戻り手順を文章で書き起こし、APIを叩くスクリプトとセットで保管しておくと、引き継ぎや障害対応の負荷が下がります。
また、タイプとは別の話ですが、APIのフロントエンドとなるアプリケーションの設計、実装は自社で担って頂くことになります。もし社内リソース不足や、APIを使った開発にご不安がある場合は、Super RAGに精通した当社パートナーがお手伝いさせて頂く方法もあります。
要件定義のフェーズでは、このA/B/Cの3類型に各機能を仕分けてみるのが有効です。タイプAは「人手でやる工程」として工数に必ず計上する、タイプBは「最初に作る台帳」として実装スコープに入れる、タイプCは「運用ドキュメント」として納品物に入れる——という当て込みで、見落としが減ります。記事末尾のマッピング表は、9カテゴリそれぞれを3類型のどこに置けばよいかを並べた早見表として作っています。
機能カテゴリは単体で見ても便利ですが、実際の業務では複数のカテゴリを組み合わせて初めて価値が出るものがほとんどです。ここでは代表的な5つの組み合わせパターンを、機能カテゴリの観点から短く整理します。詳しいシナリオは第2回および今後のユースケース回(第7〜9回を予定)に委ねます。
① 登録済ドキュメントへの問い合わせ
組み合わせ:認証 + ファイル操作(事前登録)+ チャット操作。 社内規程・マニュアル・仕様書をフォルダに登録しておき、自社業務システムから質問を投げて回答を受け取るパターンです。パターン①(Super RAG中心)の最も一般的な使い方で、AIアシスタントの設定だけはUIで先に済ませておきます。
② FAQ等の定期更新ファイルの入れ替え
組み合わせ:認証 + ファイル操作(検索→削除→登録)。 頻繁に更新される参照ファイルを、古い情報を残さず安全に入れ替える運用です。「ファイル名で検索 → 旧IDを取得して削除 → 新ファイルを登録」というループを、管理者権限のサービスアカウントで実行します。タイプCの運用設計(命名規則・頻度・戻し方)が品質を決めます。
③ ドキュメント処理機能だけを利用(自社RAG基盤への組み込み)
組み合わせ:認証 + ドキュメント処理(document-extract → chunking)。 ファイルから構造化テキストを取り出してチャンク化するところまでをSuper RAGに任せ、得られたチャンクを自社のベクターDBへ格納します。パターン③(前処理特化)の核となる組み合わせで、自社の検索・LLM資産はそのまま活かせます。
④ 検索機能だけを利用(自社LLMで回答生成)
組み合わせ:認証 + ファイル操作(事前準備)+ 検索(retrieve)。 登録済みドキュメントに対して、自社システム側からクエリを投げて関連チャンクのみを取得し、自社のLLMで回答を組み立てます。パターン②(検索特化)の代表構成で、Difyのようなワークフローツールから呼ぶ形がよく取られます。
⑤ ユーザーの一括メンテナンス
組み合わせ:認証 + ユーザー操作 + グループ操作。 人事異動や組織再編に伴うユーザーの登録・削除・所属変更を、自社のユーザー管理マスタからまとめて実行します。重複登録・最後の管理者削除不可・自分自身の削除不可といったエラー条件への分岐を実装する必要があり、タイプB(自社マスタ管理推奨)とタイプC(運用設計)の両方が絡む組み合わせです。
ここまでの内容を1枚にまとめた早見表です。要件定義や役割分担の議論で、自社のユースケースに当てはめながらチェックリスト的にお使いください。
各カテゴリについて、「API有無」「UI必須事項(タイプA)」「自社で持つべき台帳(タイプB)」「運用設計の論点(タイプC)」の4列でまとめています。
| カテゴリ | API有無 | UI必須事項(A) | 自社で持つべき台帳(B) | 運用設計の論点(C) |
|---|---|---|---|---|
| 認証 | ○ | — | 個々人のサービスアカウントの管理 | トークン更新ポリシー(頻度・障害時の再取得) |
| ユーザー操作 | ○ | — | 管理者のユーザー管理マスタ(必須) | エラーハンドリング設計(重複・最後の管理者・自己削除) |
| グループ操作 | ○ | グループ初回作成はUI推奨 | グループID台帳 | グループ統廃合・メンバー移管の手順設計 |
| フォルダ操作 | ○ | — | フォルダID台帳 | フォルダ命名規則・所有グループの設計 |
| ファイル操作 | ○ | — | ファイルID台帳(再登録でID変動) | 定期更新ファイルの入れ替え運用ルール |
| 添付ファイル操作 | ○ | — | — | 添付とフォルダ登録の使い分け方針 |
| チャット操作 | △ | AIアシスタント設定(必須) | アシスタントIDの台帳 | AIアシスタントの初回セットアップ手順 |
| ドキュメント処理 | ○(v3.3) | — | チャンク保存先の自社DB設計 | ファイル更新時のアップデート設計 |
| 検索 | ○ | — | 対象ファイルIDのリスト | retrieve呼び出し権限・対象ファイルID集合の管理 |
「○」はAPIで操作可能、「△」は一部UI操作必須、「太字」はとくに見落としやすい項目です。社内議論で「うちはどこを誰が担うか」を決める際の出発点にお使いください。基本的に、Super RAGのUI上で一元的にアカウント管理、データ管理するならローカルでの台帳管理は不要です。常にSuper RAG上のデータを最新とし、ローカルに同期すれば良いからです。しかし、ローカル主体でAPIを通じてSuper RAG上のアカウントやデータを更新したり、Super RAGから取得した情報にローカル情報を紐づけて運用する場合は、識別子を関連付ける台帳管理が必要となります。
なお、本表に挙げた以外にも、利用するユースケースによっては考慮すべき細部が出てきます。たとえば、エンベディングを自社モデルで行うか/Super RAG経由で行うか、リランクの段階を入れるか、といった選択は、本記事で扱った範囲の外側にあります。実装段階では仕様書とPoCをセットで進めてください。
次回(第4回)からは第III章「中身を可視化」に入ります。本記事の機能カタログでは、ドキュメント処理(抽出・チャンク化)と検索(retrieve)を「パターン②/③向けの中核機能」として位置づけました。第4回では、その中核のさらに最初の関門にあたるドキュメント抽出の中身を深掘りします。
主題は、Super RAGが独自開発のDocReaderとAzure Document Intelligenceをどう使い分け、どのファイル形式をどう処理しているのか —— というエンジン設計の概要紹介です。日本語PDFのレイアウト保持、表のセル単位の読み取り、図のキャプションの紐付け、スキャンPDFのOCRといった「ここで取りこぼすと後段の検索精度が頭打ちになる」関門を、エンジン側がどう設計で受け止めているかを概観します。
なお、Super RAGの抽出精度を実際のドキュメントで一般的なRAGと比べてみたい場合、無償・有償のトライアルでお客様の実データを流して結果を比較いただけます。第4回の末尾では、その比較試行のためのチェックリストを「持ち帰り検討材料」としてご用意する予定です。「機能カタログ × 抽出エンジンの設計 × 自社データでの検証」のセットで読むことで、Super RAGを業務システムに組み込む際のイメージがより具体化していくはずです。
Super RAG APIは、9つの機能カテゴリで眺めると、「UI機能の流用系」と「中核機能を部品として借りる系」の2グループに整理できます。前者は社内システムから標準のSuper RAGの機能を呼び出す用途、後者は社内システムを中心にSuper RAGのドキュメント処理や検索だけを部品として組み込む用途で、それぞれ第2回で扱ったパターン①〜③にきれいに対応します。
そのうえで重要なのが、APIだけでは完結しない「自社で担う部分」の3類型——UI操作必須(タイプA)/自社マスタ管理推奨(タイプB)/運用設計が必要(タイプC)——を要件定義の段階で仕分けることです。記事末尾のマッピング表は、この仕分けを9カテゴリに当てはめた早見表として作っています。社内の議論のたたき台に、ぜひお使いください。
<このシリーズの記事>
