
技術

前回の記事では、Super RAGの全体像と、APIを通じた3つの組み込みパターン(①Super RAG中心/②検索特化/③前処理特化)をご紹介しました。「どこまでをSuper RAGに任せ、どこから自社で制御するか」の分界点でパターンが決まる、というお話でした。
今回はそこから一歩踏み込み、それぞれのパターンが実際にどんなAPI呼び出しの流れで動くのか、そして自社のプロジェクトはどのパターンを選ぶべきなのかを解説します。パターンの選択は、開発リソースの配分、既存資産の活かし方、そして今後の拡張余地に直結します。後半では、パターン②でDifyと組み合わせた経費審査ワークフローを具体例として取り上げ、「なぜこの組み合わせが効くのか」までを掘り下げます。 記事末尾には、アーキテクチャ検討の参考として「どのパターンを選ぶべきか判断表」を用意しました。社内のRAG組み込み方針を議論する際にそのままお使いいただける形にしています。
本記事は第2回です。連載は、(I)なぜSuper RAG、(II)どう組み込むか、(III)中身を可視化、(IV)現場で何が起きているか、(V)導入判断、という5章構成で進めています。今回は第II章「どう組み込むか」の前半にあたり、次回(第3回)ではAPIの機能そのものを機能別に整理した“カタログ回”をお届けする予定です。
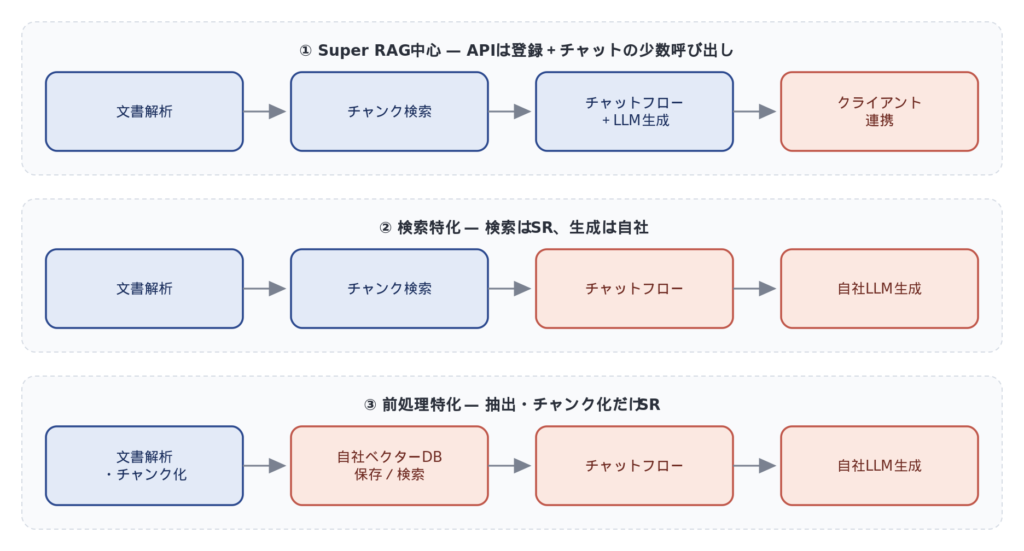
前回の復習も兼ねて、3つのパターンを「誰が何を担当するか」と「利用するAPIの粒度」の観点で並べてみます。
| パターン | 文書解析 | チャンク検索 | 回答生成 | 利用APIの粒度 |
|---|---|---|---|---|
| ① Super RAG中心 | Super RAG | Super RAG | Super RAG(LLM込み) | 大きい(登録+チャット) |
| ② 検索特化 | Super RAG | Super RAG | 自社LLM | 中(登録+検索+自社生成) |
| ③ 前処理特化 | Super RAG | 自社 | 自社LLM | 細かい(抽出・チャンク化・埋め込みを各APIで) |
ここで注目していただきたいのは、「Super RAGに寄せるほど大きな粒度で処理する”目的志向のAPI”を使い、自社に寄せるほど細かい処理を行う”機能指向のAPI”を使う」という傾向です。これは単純に手間の問題だけでなく、各段階での制御の自由度とトレードオフの関係にあります。自由度がほしいパターンでは機能的APIの呼び出し回数が増え、逆にシンプルに動かしたい場面では細かい制御が不要な目的志向のAPI呼び出しで済みます。
以降、パターンごとにAPI呼び出しの流れを具体的に見ていきます。
パターン①は、ドキュメントの登録から回答生成までをフルにSuper RAGへ委譲する構成です。自社側のシステムは、ファイルをアップロードしてチャットを投げる、という最小限の役割を担います。
API呼び出しの流れ(典型例)
1. POST /api/v3.2/collections/{collection_id}/references/ で対象ドキュメントをアップロード
2. Super RAG側で自動的に抽出・チャンク化・索引化が走る
3. POST /api/v3.2/chats/ でチャットセッションを作成
4. POST /api/v3.2/chats/{chat_id}/messages/ で質問を送信
5. 回答・エビデンス・参照チャンクがSSEでストリーム配信される
向いているケース
既存のRAG基盤がなく、とにかく早くAIアシスタント機能を社内展開したいケースです。設計・実装・運用を最小化できるため、PoCから本番までの立ち上がりが最短になります。
注意点
Super RAGでは、最終的にLLMに送信するプロンプトの細かな調整や、LLMの差し替え、回答フォーマットの厳密な制御にやや制約があります。自社側でLLMのインプット、アウトプットを細かく調整したい場合は、パターン②を検討する余地があります。
パターン②は、Super RAGの強力な文書解析・検索機能を利用しつつ、回答生成(最終プロンプト合成、文脈管理、LLM呼び出し)を自社側で制御する構成です。検索は外、生成は自社、というハイブリッドになります。
API呼び出しの流れ(典型例)
1. POST /api/v3.2/collections/{collection_id}/references/ でドキュメントをアップロード
2. 自社システム側で質問を受け取り、POST /api/v3/workflows/retrieve/ で関連チャンクを取得
3. 取得したチャンクを自社側でプロンプトに組み立てる
4. 自社の好みのLLM(OpenAI/Azure/オンプレLLMなど)で回答を生成
向いているケース
自社で既にLLM呼び出しの基盤や、ワークフロー制御の仕組み(後述するDifyのようなもの)を持っているケースです。回答のフォーマット、プロンプトチューニング、モデル切り替えを自前で握りたい要件と相性がよい構成です。
Dify経費審査が“この位置”にあたる
後半で詳しく扱いますが、Difyのワークフローから/api/v3/workflows/retrieve/を呼んで関連規定を取得し、Difyのエージェントが審査判断する、という構成はパターン②の典型例です。
パターン③は、Super RAGをドキュメント解析(抽出・チャンク化・必要に応じて埋め込み)専用として使い、ベクターDB構築と検索、回答生成はすべて自社側で制御する構成です。
API呼び出しの流れ(典型例)
1. POST /api/v3.3/actions/document-extract/ でファイルから構造化テキストを抽出
2. POST /api/v3.3/actions/chunking/ で抽出テキストをチャンクに分割
3. (任意)POST /api/v3/actions/embedding/ でチャンクをベクトル化。自社の埋め込みモデルを使う場合はこのステップを自社で実施
4. 自社ベクターDBにチャンクと埋め込みを保存
5. 質問時は自社側でベクター検索→プロンプト組み立て→自社LLMで回答生成
向いているケース
自社で育ててきたベクターDB(Milvus、Qdrant、Pineconeなど)や検索パイプラインがあり、その検索・推論の自由度は維持したまま、日本語を含む多様な文書を高精度に構造抽出する部分だけをSuper RAGに委ねたいケースです。前処理の精度は最終的な検索・回答の精度の天井を決めるため、ここを外部のエンジンに任せるのは現実的な選択肢になります。
注意点
インデックス構築からクエリ処理まで、実装範囲が最も広くなります。その代わり、チャンク分割の粒度、ベクトルの次元数、リランクの有無など、あらゆるパラメータを自社で制御できます。
ここからは、パターン②の最もイメージしやすい具体例として、Difyを使った経費審査ワークフローを取り上げます。
経費審査は、一見すると単純な突合タスクに見えて、実は複数の情報源をまたぎます。
・ 申請内容(科目・金額・支払先など)の読み取り
・ 社内の経費規定との突合
・ 計上科目コードの割り当て
・ 規定で判断できない場合の外部情報(国税局の指針、支払先の実在確認など)
・ 根拠を伴った可否判断
この流れを、Difyだけで完結させようとすると、社内文書(Word、Excel、帳票)の高精度な読み取りでつまずきます。Difyの標準RAGはテキスト中心のシンプルな検索のため、表のセルや書式のある規定文書の情報を取りこぼしがちです。また、Knowledge Pipeline機能で独自パイプラインを作ると、多大な労力を必要としながらもデータ依存になりがちで、汎用的な高精度パイプラインを作ることは困難です。
一方、Super RAGだけで完結させようとしても、外部Web情報の参照や審査プロセスのフロー制御が不得手で、エージェント的な多段推論が難しくなります。 つまり、多段推論が必要なテーマにおいて、両者の強みは補完関係にあります。Difyの「柔軟なワークフロー制御とエージェント機能」と、Super RAGの「高精度な日本語文書解析+ハイブリッド検索」を組み合わせることで、どちらかだけでは届かなかった精度とユーザー体験を実現できます。
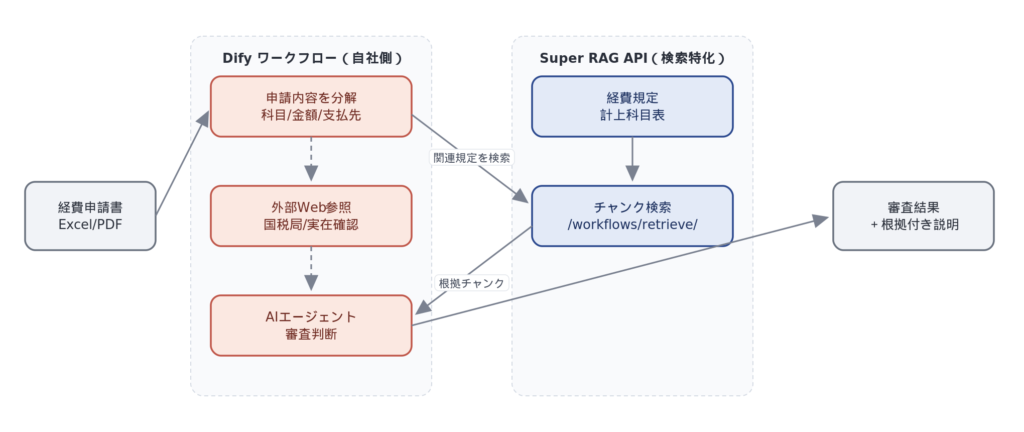
DifyのワークフローノードからSuper RAGの検索API(/api/v3/workflows/retrieve/ またはDifyのExternal Knowledge API経由*)を呼び出し、関連する経費規定や科目コード情報を取得。Difyのエージェントが申請内容・検索結果・外部Web情報を総合して、根拠付きの審査判断を出力します。Super RAGは「社内文書の読解と検索」という、一番地味で一番品質に効く部分だけを担当します。
*) External Knowledge API連携は、2026年7月(仮)にリリース予定のSuper RAG 3.4で正式に対応します。
実際のワークフローは、以下のような流れで組まれます(詳細は連載の後半で深掘り予定です)。
1. 経費申請書のSuper RAGへのアップロード
2. 申請書から科目・摘要・金額などテキスト情報を抽出
3. Super RAG経由で経費規定/科目コード表から関連チャンクを検索
4. AIエージェントが申請内容×検索結果×必要に応じた外部Web情報で審査判断
5. 審査結果と根拠をテキスト出力
6. 人の最終確認
経費審査は一例にすぎません。この構成は「社内文書の正確な理解」と「外部情報を含む多段の判断」の両方が必要な業務全般に流用できます。たとえば、社内規程と法令を突き合わせる契約レビュー、設計書と過去の障害報告を照合する技術審査、仕様書と製品カタログを突き合わせる見積支援など、「社内ナレッジ+外部情報+多段判断」の構造を持つタスクには一貫して応用が利きます。
「実際どれくらい精度が出るのか」「Dify単独/Super RAG単独/組み合わせで、どう差が出るのか」といった定量的な比較検証の結果と、ワークフローの詳細なノード構成については、連載の後半で予定している「ユースケース事例 AIエージェント連携(仮)」で深掘りします。パターン②がどう実務で機能するか、どう精度に影響するかを扱う予定です。
ここまでの内容を踏まえて、実際にパターンを選ぶ際の判断軸をまとめます。3軸の選択と、7つのチェック項目で、社内議論のたたき台としてお使いください。
パターン選定の判断フロー
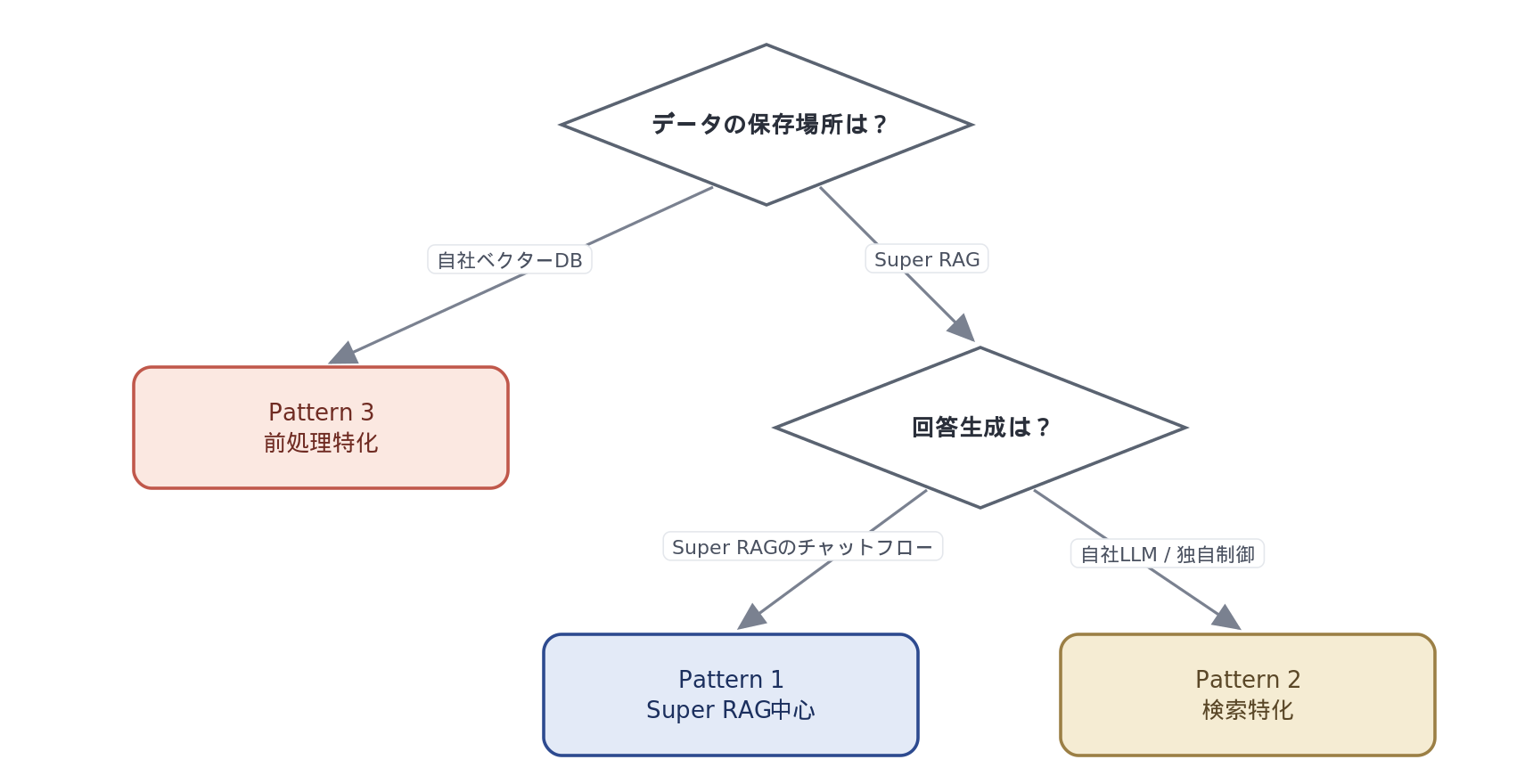
パターンは、結局のところ次の3軸の選択に帰着します。
軸1:データの保存場所はどこか
社内のベクターDBや既存検索基盤にチャンクを置きたい場合 → パターン③確定
軸2:検索はどこで実行するか
データをSuper RAGに置くなら、検索もSuper RAG側で走ります。ここは分離できません。
軸3:回答生成はどこで行うか
Super RAGのチャットフローで完結させる → パターン①/自社LLMで独自制御する → パターン②
より実務的な判断のために、以下7項目のチェック結果から向いているパターンを読み取れる早見表をご用意しました。
| 観点 | パターン①向き | パターン②向き | パターン③向き |
|---|---|---|---|
| ベクターDBの既存資産 | 無し/任せたい | 無し/任せたい | 有り/活かしたい |
| LLM選定・プロンプト調整の自由度 | 低くてよい | 高く持ちたい | 高く持ちたい |
| 外部データ境界の要件 | Super RAGに預けられる | Super RAGに預けられる | 自社システム内に閉じたい |
| 導入スピードの重視度 | 最優先 | 中 | 後回しでよい |
| 開発・運用リソース | 少ない | 中 | 十分ある |
| 既存ワークフローツールの有無 | 無し | Dify / n8n等有り | 自社製の制御基盤有り |
| コスト構造の好み | 学習コスト最小 | LLM側を自社管理 | インフラ含め自社制御 |
複数の観点で該当するパターンが、第一候補になります。完全に一つのパターンに寄り切れない場合は、パターン②から始めて、必要に応じてパターン③へ移行する方法も考えられます。
※「外部データ境界の要件」について、パターン①、②のケースでも、Super RAGをお客さまのAzure環境内にインストールすることは可能です。
次回(第3回)は、API機能カタログ — 何ができて、何は自社で担うかをお届けします。ドキュメント抽出、チャンク化、埋め込み、検索、チャット、認証、グループ管理など、Super RAG APIの機能を役割別に一覧化し、機能ごとに「どのパターンで誰が担うか」を整理します。パターン選択と合わせて読むことで、自社システムの役割分担がより具体化しやすくなる“辞書的な回”になる予定です。
そしてパターン②のDify経費審査の具体的な精度検証結果と、ワークフロー内部のノード構成の深掘りは、「ユースケース事例 AIエージェント連携(仮)」で扱います。どうぞお楽しみに。
3つの組み込みパターンは、「Super RAGに寄せるほどAPIは少なくシンプル、自社に寄せるほど呼び出しは多く細かく、その代わり制御の自由度が上がる」というトレードオフで整理できます。パターン①は導入スピード最優先、パターン②は既存LLMやワークフローツールとの柔軟な組み合わせ、パターン③は既存ベクターDB資産の活用と強い統制、がそれぞれの勝ち筋です。
Dify経費審査のようなパターン②の構成は、「社内文書の高精度な読解」と「柔軟な多段推論フロー」という、それぞれのツール単独では届かなかった領域に、組み合わせで手が届くことを示す好例です。自社のユースケースに当てはめる際は、記事末尾の判断表を起点に、どの「場所」を誰に任せるかの整理から始めてみてください。
<このシリーズの記事>
