
技術

社内ドキュメントやマニュアルをAIに参照させる「RAG(Retrieval-Augmented Generation)」は、すでに多くの企業で導入が進んでいます。しかし実際に使ってみると、「引用箇所がズレている」「表や図の情報が拾えない」「専門用語で検索が外れる」といった壁にぶつかる方も多いのではないでしょうか。
Super RAGは、こうした“実用で詰まる”課題を乗り越えるために設計されたRAG基盤です。本記事では、通常のRAGとの差別化ポイントを中心に、Super RAGの技術的な工夫を整理してご紹介します。
本記事はSuper RAGの全体像と差別化ポイントをまとめた連載の第1回です。以降の連載では、(I) APIによる組み込みの設計判断、(II) 精度を支える技術の中身(抽出・検索・回答戦略)、(III) 業務別のユースケース、(IV) PoC〜本番導入の実務、という順で段階的に掘り下げていく予定です。
Super RAGは、大きく2つのパイプラインで構成されています。

Indexingパイプライン(事前準備):ドキュメントを取り込み、構造を保ったまま抽出・分割し、複数の検索エンジンへ索引化します。
Retrievalパイプライン(回答時):ユーザーの質問を受けて、クエリ管理・ハイブリッド検索・リランクを経て、LLMで根拠付きの回答を生成します。 ここでのポイントは、抽出・索引化・検索・生成が一つの品質チェーンとして連動していることです。どこか一段でも質を落とすと最終回答に響くため、各段階を精緻に設計しているのが特徴です。
Super RAGが「通常のRAG」と異なる主な点を表で整理しました。
| 観点 | 通常のRAG | Super RAG |
|---|---|---|
| ドキュメント理解 | プレーンテキスト化 | AI-OCR内蔵でイメージPDFに強く、セクション・表・図・FAQ・用語集の構造を保持 |
| チャンク分割 | 固定長でブツ切り | サイズ制限+重なり(overlap/windowing)で文脈を保持 |
| 検索方式 | ベクトル検索のみが多い | ベクトル検索+全文検索のハイブリッドを並列実行 |
| 精度制御 | 検索結果をそのまま使う | Rerank(再スコアリング)で上位を選び直す |
| 回答経路 | 常に同じ手順で回答 | 質問タイプを5分類(Direct / Single-hop / Multi-hop / Specific request / Dictionary)で自動判定し、対応する回答戦略(Single-hop / Multi-hop / Direct / Dictionary)を選択 |
| 日本語対応 | OCR自体が含まれないか、含まれていても日本語の精度が低い | 日本語ドキュメント向けにOCR/構造抽出を最適化 |
処理フローで並べると、違いはより明確です。

とくに効果が大きい3点を補足します。
1. 構造を保った抽出 たとえば仕様書の「章立て」「表のセル」「図のキャプション」は、そのままテキスト化するとバラバラになって意味が失われがちです。Super RAGはAzure Document Intelligenceや独自開発のDocReaderを使い、構造を維持したまま取り込みます。これが後段の検索精度の土台になります。
2. ハイブリッド検索 「要するにどういう概念か」を問う質問にはベクトル検索が強く、「型番XYZ-123」のような厳密な語を引くには全文検索が効果的です。両方を並列に走らせて統合することで、どちらのタイプの質問にも強くなります。
3. アダプティブな回答経路 単純な事実確認は1回の検索で済みますが、複数ステップを要する質問は段階的な検索が必要です。Super RAGはまず質問をDirect / Single-hop / Multi-hop / Specific request / Dictionaryの5タイプに自動分類し、そのうえで対応する回答戦略(Single-hop / Multi-hop / Direct / Dictionary)を選んで最短経路の回答を返します。
Super RAGを構成する主な技術を層別に整理します。
| 層 | 採用技術 |
|---|---|
| ドキュメント抽出(AI) | Azure Document Intelligence、lib-docreader(YOLO+OCR+表/図モデル) |
| ドキュメント抽出(ライブラリ) | pandas、PyMuPDF、Unstructured、python-pptx |
| ベクターDB | Milvus(HNSW / IVF / AUTOINDEXなど) |
| 全文検索 | Elasticsearch(BM25) |
| グラフDB(任意) | Neo4j |
| メタデータストア | PostgreSQL |
| 埋め込みモデル | Azure OpenAI Embeddings(1536 / 3072次元) |
| 対話LLM | Azure OpenAI Reasoning Model(gpt-4.1など、ストリーミング対応) |
| リランク | Cohere Rerank(Azure経由含む)/LLMリランク |
| フレームワーク | LlamaIndex、Langchain(ラッパーとして利用) |
| 観測性 | OpenTelemetry、OpenLIT(任意) |
| 設定管理 | pydantic-settings+ファクトリ方式 |
クラウドマネージドサービスとオープンソースを組み合わせ、必要に応じてコンポーネントを入れ替えることで、常にベストなパフォーマンスを出す構成になっています。
補足:独自の文書抽出エンジン「DocReader」が効く理由
技術スタックで挙げた lib-docreader(DocReaderの内部ライブラリ名)は、Super RAGの文書抽出を支える中核コンポーネントです。単体の「OCR付きPDFパーサ」ではなく、複数の専門モデルを一本のパイプラインに束ねた”文書理解エンジン“として動作します。エンジニア視点の細部には踏み込まず、利用する立場から見た利点を整理すると、次の4点が挙げられます。
1. ファイル形式を問わず共通品質で抽出できる
PDFはもちろん、Word・Excel・PowerPoint、画像(PNG/JPEG)、HTMLまで、入力に応じて最適なローダーが自動的に選ばれます。Officeファイルは内部で一度PDFに変換してから共通パイプラインに流し込むため、「形式の違いによって抽出品質がばらつく」従来のRAG導入でよくある悩みを抑えられます。
2. レイアウト・OCR・表/図をまとめて理解する
紙面上のどこが本文で、どこが表で、どこが図なのかをまず画像解析で把握し、そのうえで領域ごとに最適な処理(OCR/表構造の復元/図キャプションの抽出)を走らせます。単純にテキストを読み取るだけでなく、「表のセル単位で引用する」「図のキャプションだけを拾う」といった、通常のOCRでは難しい使い方に応えられるのが特徴です。結果として、後段のチャンク分割や検索が意味のある単位で動けるようになります。
3. 日本語ドキュメントに最適化されている
レイアウト解析・OCRともに日本語文書を前提にチューニング済みです。縦横混在のレイアウト、和欧混在のテキスト、和文特有の句読点や記号も安定して扱えるため、日本語マニュアル・議事録・規程類を扱うプロジェクトで効果が出やすい領域です。
4. OCRバックエンドを用途に応じて切り替えられる
ローカル完結型のOCRと、クラウドマネージド型のOCRの適材適所で切り替える設計になっています。セキュリティ・コスト・品質のバランスを取りやすい構成です。これらが組み合わさることで、DocReaderは「入口の抽出品質が、最終回答の品質を決める」というSuper RAGの設計思想を、具体的な技術として体現しています。後段のチャンク分割・ハイブリッド検索・回答生成パイプラインがどれほど洗練されていても、入口で構造が崩れれば精度の上限は下がってしまう——その入口を担うのがDocReaderです。
Super RAGの特徴が活きやすい場面をいくつかご紹介します。
日本語マニュアル・社内文書のナレッジ検索
DocReaderが日本語ドキュメントに最適化されているため、日本語のマニュアルや議事録、仕様書など「日本語+図表が多い素材」を扱うプロジェクトに適しています。
製造業・研究開発部門の技術文書活用
図表・数式・レイアウトが複雑な技術文書でも、構造を保った抽出により高精度に検索できます。型番や試薬名といった厳密な語も全文検索側でカバーされます。
サポート業務・FAQ/用語集を持つ業務
FAQや用語集を専用処理パイプラインで扱えるため、既存のFAQデータや用語辞書を活用して精度を向上できます。辞書を使えば、社内用語の定義を自動的にプロンプトに挿入してLLMが理解した状態で検索・推論する、といった運用も可能です。
複数ステップの推論を要する調査業務
Multi-hop戦略により、「Aの条件を満たすBは何か、その背景は」といった多段的な質問の精度が向上します。1回の検索では根拠を取りこぼしやすいケースで効果を発揮します。ただし、複雑な多段推論はAIエージェント/ワークフローを構築する方が精度が出る場合があります。その場合はAPIを通じて専用プラットフォームと連携するなど、柔軟なアーキテクチャを採用できます。
ここまでご紹介したSuper RAGの強みは、APIを通じて自社システムに組み込むことで、さらにユースケースの幅を広げられます。Super RAGは標準のUIだけでなく、既存の業務システム、ワークフローツール、AIエージェントから呼び出せる設計になっており、「高精度なRAGを一つの部品として組み込む」ことが可能です。
Super RAG APIの組み込みは、責務の分担によって大きく3パターンに整理されます。どこまでをSuper RAGに任せ、どこから自社側で制御するか、その分界点でパターンが決まります。
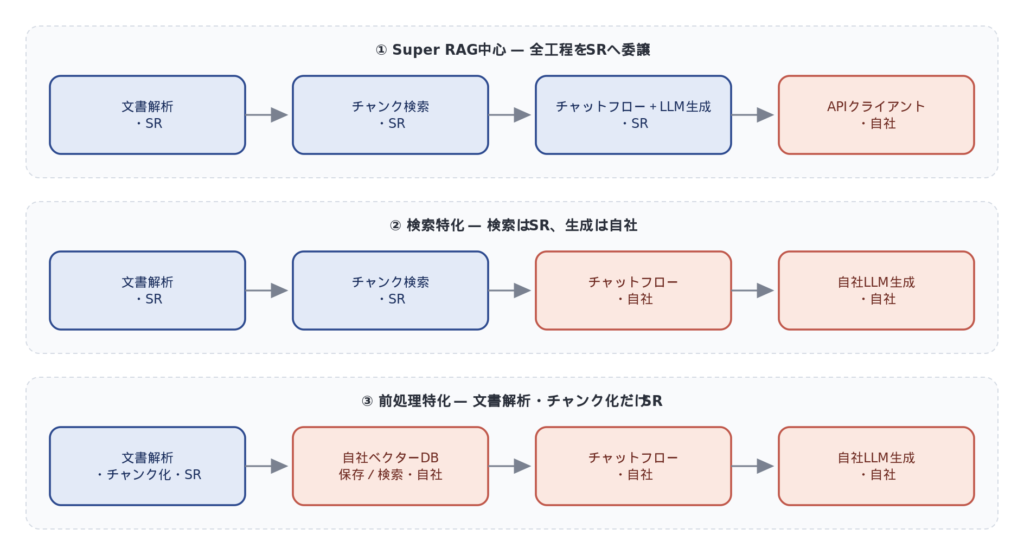
| パターン | 責務分担 | 向いているケース |
|---|---|---|
| ① Super RAG中心 | 文書解析・検索・回答生成までフルにSuper RAGへ委譲 | とにかく早くRAGを稼働させたい、運用負荷を最小化したい |
| ② 検索特化 | 前処理と検索はSuper RAG、回答生成は自社LLM | 既存LLMやプロンプトをコントロールしつつ検索だけ強化したい |
| ③ 前処理特化 | 文書解析・チャンク化だけSuper RAG、ベクターDBと推論は自社 | 独自RAG基盤を育てており、前処理エンジンとして組み込みたい |
API経由では、次のような操作が概ねカバーされています。
・ユーザー/グループ管理:アカウント作成・削除、認証、権限制御
・フォルダ/ファイル管理:アップロード、更新、削除、一覧取得
・チャット実行:チャットセッション作成とクエリ送信〜回答取得
・ドキュメント前処理:構造化テキストへの抽出・チャンク化(document-extract / chunking)
・チャンク検索:質問に対する関連チャンクをスコア付きで返却(retrieve)
・埋め込み生成:テキストのベクトル化これらを組み合わせることで、社内システム側の権限に合わせた参照範囲制御や、バッチ処理的な運用も実現できます。
APIを活用すると、たとえば以下のような応用が視野に入ります。
・社内システム直結のQ&A:既存の業務アプリUIから、Super RAG内の参照データに問い合わせる
・参照データの自動メンテナンス:定期更新される参照ファイルを古い情報を残さず入れ替える運用
・ワークフローツールと連携したAIエージェント:Difyなどのエージェント基盤と組み合わせ、経費審査のような多段推論タスクを半自動化
・「文書対文書」の類似事例検索:作業計画書から過去の事故・ヒヤリハット事例を先回りで抽出する安全管理基盤など
・既存文書からのFAQ半自動生成:規程やマニュアルから根拠付きQ&Aを生成し、レビュー・公開までを一貫管理
・既存RAG基盤の精度強化:自社のベクターDBや推論パイプラインはそのままに、文書解析エンジンだけ差し替える
いずれも、「Super RAGを単体プロダクトとして導入する」のではなく、既存資産を活かしながら必要な部分だけを取り込む使い方です。 イメージとして、Dify(AIエージェント基盤)と連携した経費審査の例を示します。これはパターン②「検索特化」の一例で、Difyのワークフロー制御と、Super RAGの高精度な文書解析+チャンク検索を組み合わせた構成です。
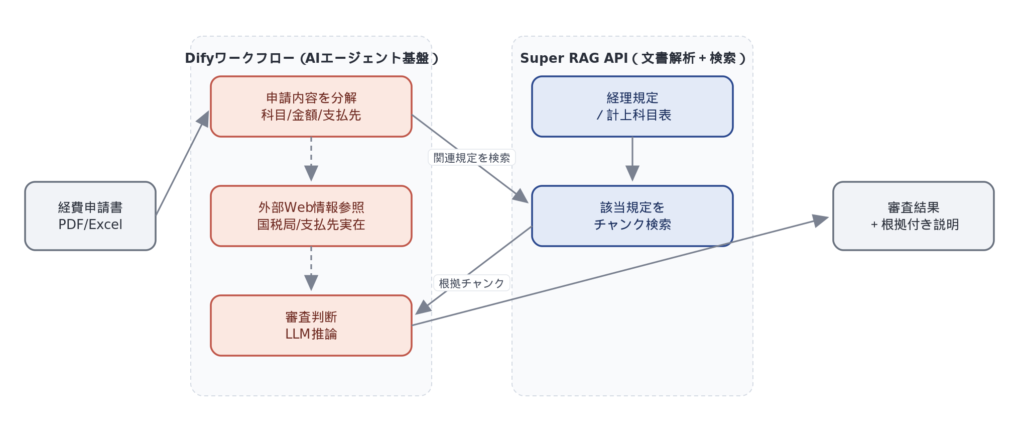
経費申請を受け取ったDifyワークフローが、経理規定や計上科目表の参照をSuper RAGに依頼し、その根拠チャンクと外部Web情報(国税局・支払先実在確認)を合わせてLLMが審査判断を行います。Super RAGは“社内文書の理解”という高精度な文書解析が必要な部分を担い、ワークフロー制御と最終推論は既存ツールに任せる、という分担です。
次回の記事では、これら3つのアーキテクチャパターンごとに、実際のAPI呼び出しの流れや、Dify連携による経費審査ワークフローなどの具体例を掘り下げてご紹介します。自社システムにSuper RAGを組み込む際の設計判断の勘所を、よりイメージしやすい形でお伝えする予定です。
さらに以降の回では、日本語ドキュメント抽出・ハイブリッド検索・回答戦略といった“精度の中身”、製造/サポート/AIエージェント連携など業務別のユースケース、そしてPoC設計や評価指標の実務まで、順に扱っていく予定です(構成は進行に応じて調整する場合があります)。
Super RAGは、「抽出の質が検索の質を決め、検索の質が回答の質を決める」という一貫した設計思想のもとに構築されています。ドキュメント構造の保持、ハイブリッド検索、リランク、適応的な回答経路という4つの工夫が重なり合うことで、通常のRAGでは取りこぼしがちな情報にも届く品質を実現しています。 さらにAPIを通じて、この品質を既存システムやAIエージェントの中に“部品”として取り込めることも、Super RAGの大きな特徴です。RAG導入で精度の壁に当たっている方、日本語ドキュメントを本格的に活用したい方、そしてカスタムAIワークフローの中核を探している方は、ぜひSuper RAGの活用をご検討ください。
<このシリーズの記事>

