
technology

"RAG (Retrieval-Augmented Generation)," which uses AI to access internal documents and manuals, is already being adopted by many companies. However, when actually using it, many people encounter obstacles such as "the quoted sections are inaccurate," "information from tables and figures cannot be retrieved," and "searches are inaccurate due to specialized terminology."
Super RAG is a RAG platform designed to overcome these practical challenges. This article will summarize and introduce the technical innovations of Super RAG, focusing on its points of differentiation from conventional RAGs.
This article is the first in a series summarizing the overall picture and differentiating points of Super RAG. Subsequent articles in this series will delve into the following topics in stages: (I) Design decisions for embedded systems using APIs, (II) The details of the technologies supporting accuracy (extraction, search, and response strategies), (III) Use cases for different business processes, and (IV) Practical aspects from PoC to production deployment.
Super RAG consists of two main pipelines.

Indexing pipeline (preparation)This process involves importing documents, extracting and splitting them while maintaining their structure, and indexing them for multiple search engines.
Retrieval pipeline (when responding): We receive user questions, perform query management, hybrid search, and reranking, and then generate evidence-based answers using LLM. The key point here is:Extraction, indexing, searching, and generation are interconnected as a single quality chain.That's the point. Because even a slight drop in quality at any stage will affect the final answer, each stage is meticulously designed.
The main differences between Super RAG and "regular RAG" are summarized in the table.
| perspective | Regular RAG | Super RAG |
|---|---|---|
| Document comprehension | Convert to plain text | With built-in AI-OCR, it excels at handling image-based PDFs and preserves the structure of sections, tables, figures, FAQs, and glossaries. |
| Chunk splitting | Cut into pieces of a fixed length | Context is maintained through size limitations and overlapping/windowing. |
| Search method | Most searches are vector-only. | A hybrid approach combining vector search and full-text search, executed in parallel. |
| Precision control | Use the search results as they are. | Rerank (re-scoring) to select the top performers again. |
| Response route | Always answer using the same procedure | The system automatically identifies the question type into five categories (Direct / Single-hop / Multi-hop / Specific request / Dictionary) and selects the corresponding response strategy (Single-hop / Multi-hop / Direct / Dictionary). |
| Japanese language support | Either OCR itself is not included, or if it is included, its accuracy in Japanese is low. | Optimized OCR/structure extraction for Japanese documents |
The differences become clearer when you arrange them in a processing flow chart.

I will add three points that are particularly effective.
1. Extraction while preserving the structure For example, the "chapter outlines," "table cells," and "figure captions" in a specification document tend to become fragmented and lose their meaning if they are simply converted to text. Super RAG uses Azure Document Intelligence and its proprietary DocReader to import the data while maintaining its structure. This forms the foundation for the subsequent search accuracy.
2. Hybrid Search Vector search is effective for questions that ask "What is the concept in essence?", while full-text search is effective for finding precise terms like "model number XYZ-123". Running both in parallel and integrating them makes the search more powerful for both types of questions.
3. Adaptive response pathways Simple fact-checking can be done with a single search, but questions requiring multiple steps necessitate a step-by-step search. Super RAG first automatically classifies questions into five types: Direct, Single-hop, Multi-hop, Specific request, and Dictionary. Then, it selects the corresponding answer strategy (Single-hop, Multi-hop, Direct, or Dictionary) to return the shortest path to the answer.
The main technologies that make up Super RAG are organized by layer.
| layer | Technology adopted |
|---|---|
| Document extraction (AI) | Azure Document Intelligence,lib-docreader(YOLO + OCR + Table/Figure Model) |
| Document extraction (library) | pandas, PyMuPDF, Unstructured, python-pptx |
| Vector DB | Milvus (HNSW/IVF/AUTOINDEX etc.) |
| Full-text search | Elasticsearch (BM25) |
| Graph database (optional) | Neo4j |
| Metadata store | PostgreSQL |
| Embedded model | Azure OpenAI Embeddings (1536/3072 dimensions) |
| Dialogue LLM | Azure OpenAI Reasoning Model (supports streaming, including GPT-4.1) |
| Rerank | Cohere Rerank (including via Azure) / LLM Rerank |
| framework | LlamaIndex, Langchain (used as a wrapper) |
| Observability | OpenTelemetry, OpenLIT (optional) |
| Settings management | pydantic-settings + factory method |
By combining cloud-managed services and open source, and by swapping components as needed, the system is configured to always deliver the best performance.
Supplement: Why our proprietary document extraction engine "DocReader" works
The lib-docreader (the internal library name of DocReader) listed in the technology stack is a core component that supports Super RAG document extraction. It is not a standalone "PDF parser with OCR",A "document comprehension engine" that combines multiple specialized models into a single pipeline.“It operates as follows. Without going into the details from an engineer's perspective, the advantages from a user's point of view can be summarized as follows:
1. Extraction can be performed with consistent quality regardless of file format.
In addition to PDFs, the system automatically selects the optimal loader based on the input, including Word, Excel, PowerPoint, images (PNG/JPEG), and HTML. Office files are converted to PDF internally before being fed into the common pipeline, thus mitigating the common problem of inconsistent extraction quality due to format differences, which is often seen with traditional RAG implementations.
2. Understand layout, OCR, and tables/figures together.
First, image analysis is used to determine which parts of the page are text, tables, and figures. Then, the most appropriate processing (OCR/table structure reconstruction/figure caption extraction) is applied to each area. It's not just about reading text,"Quote data cell by cell in a table" "Extract only the captions from figures"Its key feature is its ability to handle uses that are difficult with conventional OCR. As a result, subsequent chunking and searching can operate in meaningful units.
3. Optimized for Japanese documentation
Both the layout analysis and OCR functions are tuned specifically for Japanese documents. Because it can reliably handle mixed vertical and horizontal layouts, mixed Japanese and Western text, and Japanese-specific punctuation and symbols, it is particularly effective in projects dealing with Japanese manuals, meeting minutes, and regulations.
4. The OCR backend can be switched depending on the application.
The system is designed to switch between locally-based OCR and cloud-managed OCR, depending on the specific application.Balance of security, cost, and qualityThis configuration makes it easy to access. When these elements are combined, DocReader becomes "The quality of the initial extraction determines the quality of the final response.This embodies the Super RAG design philosophy as a concrete technology. No matter how sophisticated the subsequent chunking, hybrid search, and answer generation pipelines are, if the structure breaks down at the entry point, the upper limit of accuracy will decrease—and DocReader is responsible for that entry point.
Here are a few situations where the Super RAG feature is particularly useful.
Knowledge search for Japanese manuals and internal company documents
Because DocReader is optimized for Japanese documents, it is suitable for projects that handle materials with a lot of Japanese text and diagrams, such as Japanese manuals, meeting minutes, and specifications.
Utilization of technical documents in manufacturing and research and development sectors
Even technical documents with complex diagrams, formulas, and layouts can be searched with high accuracy through structure-preserving extraction. Precise terms such as model numbers and reagent names are also covered by the full-text search.
Support work and work involving FAQs/glossaries.
Because FAQs and glossaries can be handled through a dedicated processing pipeline, accuracy can be improved by utilizing existing FAQ data and glossary dictionaries. Using dictionaries, it's also possible to automatically insert definitions of internal company terms into prompts, allowing LLM to understand them and then perform searches and inferences.
Research work requiring multiple steps of reasoning
The multi-hop strategy improves the accuracy of multi-step questions such as "What is B that satisfies condition A, and what is the background?". It is effective in cases where evidence is easily missed in a single search. However, for complex multi-step inference, building an AI agent/workflow may yield better accuracy. In such cases, a flexible architecture can be adopted, such as integrating with a dedicated platform via an API.
The strengths of Super RAG that we have introduced so far are:Integrating into our own system via APIThis further expands the range of use cases. Super RAG is designed to be called not only from the standard UI, but also from existing business systems, workflow tools, and AI agents, making it possible to "integrate high-precision RAG as a single component."
The integration of the Super RAG API can be broadly categorized into three patterns based on the division of responsibilities. The pattern is determined by the boundary between what is entrusted to Super RAG and what is controlled by your company.
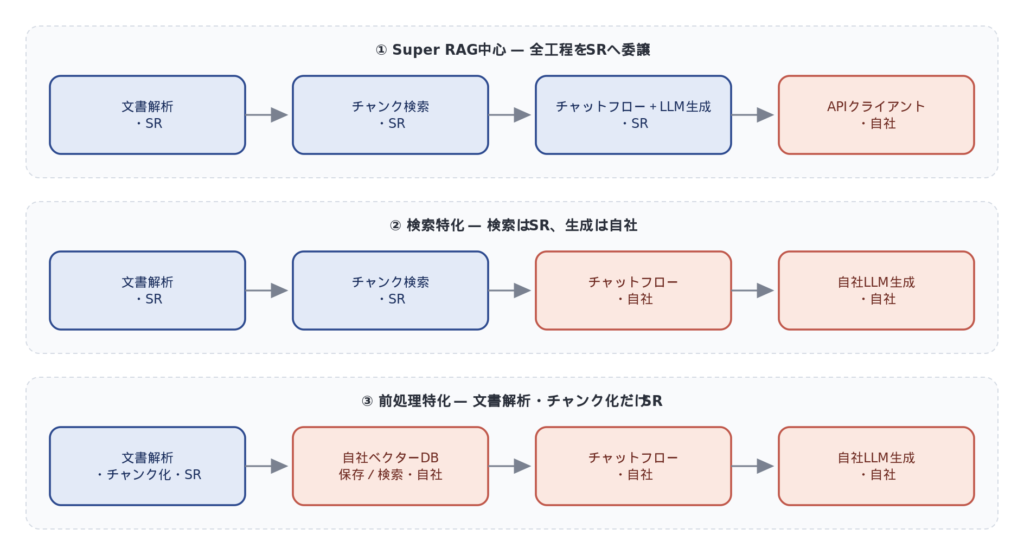
| pattern | Division of Responsibilities | Suitable cases |
|---|---|---|
| ① Mainly Super RAG | Document analysis, search, and response generation are fully delegated to Super RAG. | We want to get RAG up and running as quickly as possible and minimize the operational burden. |
| ② Search-focused | Preprocessing and searching are handled by Super RAG, while answer generation is handled by our in-house LLM. | I want to enhance the search function while maintaining control over existing LLMs and prompts. |
| ③ Specialized in pre-processing | Document analysis and chunking are handled by Super RAG, while vector database and inference are handled in-house. | We are developing our own RAG platform and would like to incorporate it as a preprocessing engine. |
The following operations are generally covered via the API:
・User/Group ManagementAccount creation/deletion, authentication, permission control
Folder/file managementUpload, update, delete, retrieve list
Execute chat: Create a chat session and send a query ~ retrieve a response
Document preprocessingExtracting and chunking text into structured text (document-extract / chunking)
Chunk search: Returns relevant chunks for the question with scores (retrieve)
• Embedding generationBy combining these methods, such as text vectorization, it becomes possible to control the scope of access according to the permissions on the internal system side, and to perform batch processing operations.
By utilizing APIs, the following applications come into view, for example:
・Q&A directly linked to the company's internal system: Query reference data within Super RAG from the existing business application UI.
・Automatic maintenance of reference data: A system that replaces reference files that are updated regularly without retaining old information.
AI agents integrated with workflow toolsBy combining it with agent-based platforms such as Dify, multi-stage inference tasks such as expense review can be semi-automated.
- Search for similar cases between documents.: A safety management platform that proactively extracts past accident and near-miss incidents from work plans, etc.
- Semi-automatic generation of FAQs from existing documents: Generates evidence-based Q&A from regulations and manuals, and manages the entire process from review to publication.
・Enhanced accuracy of existing RAG infrastructure: Keep the company's vector database and inference pipeline as they are, and only replace the document analysis engine.
In all cases, the approach is not to "introduce Super RAG as a standalone product,"Leverage existing assets while incorporating only the necessary parts.Here's how to use it. As an example, we'll show an example of expense review in conjunction with Dify (an AI agent platform). This is an example of Pattern 2, "Search-Focused," which combines Dify's workflow control with Super RAG's high-precision document analysis + chunk search.
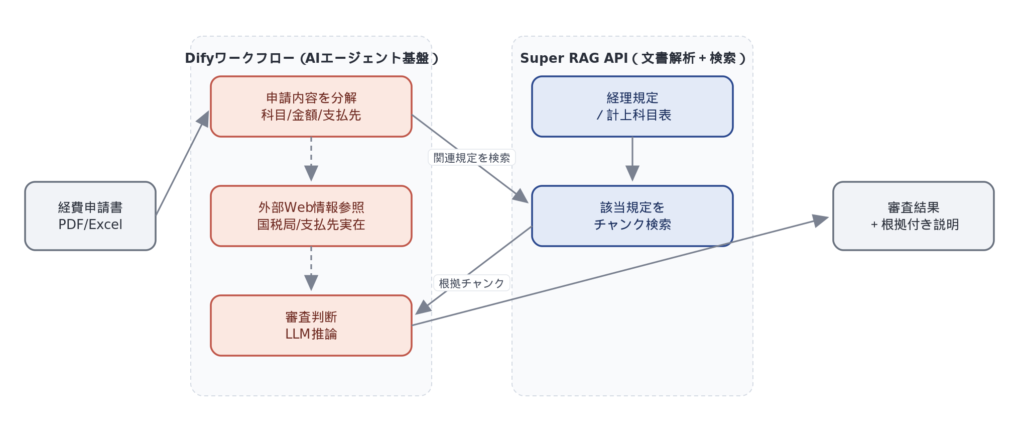
The Dify workflow, upon receiving an expense claim, requests Super RAG to refer to accounting regulations and account lists. LLM then reviews and makes a decision based on this information, combining it with external web information (National Tax Agency, verification of payee existence). Super RAG is responsible for the part requiring high-precision document analysis, specifically "understanding internal documents," while workflow control and final reasoning are left to existing tools.
In the next article, we will delve into specific examples for each of these three architectural patterns, including the actual API call flow and expense review workflows using Dify integration. We aim to provide a more easily understandable explanation of the key design considerations when integrating Super RAG into your own system.
In subsequent sessions, we will sequentially cover the "substances of accuracy," such as Japanese document extraction, hybrid search, and answer strategies; use cases for different business functions, such as manufacturing, support, and AI agent integration; and the practical aspects of PoC design and evaluation metrics (the structure may be adjusted as we progress).
Super RAG is built on the consistent design philosophy that "the quality of extraction determines the quality of search, and the quality of search determines the quality of response." Through the combined efforts of four key features—document structure preservation, hybrid search, reranking, and adaptive response paths—it achieves a quality that reaches information often missed by conventional RAGs. Furthermore, a major feature of Super RAG is its ability to integrate this quality as a "component" into existing systems and AI agents via its API. If you're facing accuracy limitations with RAG implementation, want to make full use of Japanese documents, or are looking for the core of a custom AI workflow, please consider using Super RAG.
<Articles in this series>

