
technology


Hello. I am in charge of Cinnamon AI public relations.
Cinnamon AI is developing a product called Aurora Clipper that uses natural language processing technology, and it has various uses such as obtaining dates and people's names with specific context, extracting key points from long sentences, and classifying text. We provide products used in
We have around 100 AI researchers, and among them, a team specializing in natural language processing is constantly improving the AI model that forms the basis of Aurora Clipper. In this article, our PM will introduce the overview of the Japanese version of ELECTRA, which has been released as a result of research related to natural language processing technology.
As the name suggests, natural language processing analyzes the meaning of words by treating them as numerical information.
This technology gained particular attention in May 2018 when Google BrainBERT (Bidirectional Encoder Rpresentations from TThis technology was inspired by the proposal of an algorithm called ``ransformers'', which has dramatically improved the accuracy of existing natural language processing tasks.
In conventional natural language processing, neural networks are constructed for each purpose, such as text classification or question and answer, but BERT uses transfer learning to perform language models pre-trained from large amounts of unlabeled texts such as Wikipedia, which can be used for various purposes. tasks can now be performed universally. As a result, highly accurate natural language processing can now be performed without the need for large amounts of labeled data. Chatbots using BERT have been put into practical use in business settings, and the number of cases in which they are used in actual work is increasing.
Since the introduction of BERT, many models based on BERT have been proposed, such as XLNet and RoBERTa, but there was one major problem. The problem is that it takes time to train a language model. Currently, it takes several months to build a language model by yourself using just one GPU. Therefore, it takes a lot of time to build a language model specific to Japanese, and currently a language model for BERT that is pre-trained on Japanese documents from Wikipedia, which is publicly available, is used for general purposes. .
On the other hand, the language model for BERT trained using WikiPedia data is still difficult to achieve accuracy in industries where special terminology is frequently used, such as the manufacturing and insurance industries. However, it is difficult to make the investment decision to build an industry-specific BERT model because building an industry-specific language model is expensive and time-consuming, and there is no guarantee of accuracy improvement. There is also.
Summary①
✔ Natural language processing is rapidly progressing with BERT as the starting point
✔ On the other hand, it takes a lot of time to train a language model, and BERT, which supports Japanese, is often based on Wikipedia, which is a common corpus.
✔ Therefore, there may not be sufficient language analysis performance for tasks that use terminology that depends on a special domain, so it is necessary to build an industry-specific language model, but it is difficult to make investment decisions.
ELECTRA (Efficiently Learn an income Ecoder that Classifies Token Replacements Accurately) in May 2020 from Google Brain to ICLR (The Iinternational Conference on Learning RThis is an algorithm that is the successor to BERT, which was announced at
ELECTRA is a generative adversarial network (GAN) that has been used in the field of image recognition.Genergetic Adversarial NThis is an application of the idea of ``Network'' to the learning of language models.

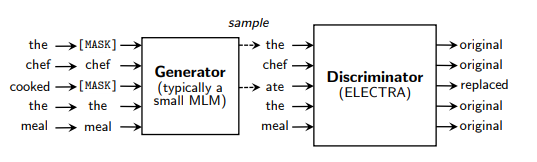 Quoted from ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS (ICLR 2020)
Quoted from ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS (ICLR 2020)
A major feature is that compared to RoBERTa, the successor of BERT, it can achieve the same accuracy with about 1/4 the amount of training data and less data. Another main feature is that inference processing can be performed at high speed.
However, the language model released by Google Brain was built using the English version of Wikipedia and websites, and it was unclear what effect it would have on Japanese. Therefore, as part of our research activities, we used the Japanese version of Wikipedia to build a language model for ELECTRA specialized in Japanese. As a result, we were able to obtain results that compared to BERT, the accuracy (F value) increased by 3 to 201 TP3T using data from projects that we have implemented so far. We also confirmed that the 12GB of Wikipedia data used for pre-training could be completed in about 5 days with a single GPU, and that inference could be performed using only the CPU at about 1/4 the speed of BERT.
Until now, BERT inference has been extremely time-consuming, and for companies like ours that implement AI on-premises, it is essential for customers to implement GPUs, but at the same time it is a major barrier to implementation. It was. Therefore, we expect that ELECTRA, which can perform inference on a CPU, can significantly lower the barriers to introducing AI on-premises.
ELECTRA has brought us the wonderful results mentioned above, so we have decided to release the Japanese version of ELECTRA to the public in order to further promote natural language processing in Japan.
https://huggingface.co/Cinnamon/electra-small-japanese-generator
https://huggingface.co/Cinnamon/electra-small-japanese-discriminator
We hope that this will promote the use of business AI using natural language processing, not only at our company, but throughout Japan!
In the future, we will acquire domain knowledge and provide highly accurate business AI by building language models specific to each industry and customer, and building a knowledge system tailored to the customer environment.
In addition, we will localize our cutting-edge research into Japanese and work hard to help our customers experience greater operational efficiency!
✔ By building the Japanese version of ELECTRA, the accuracy of past projects has improved and the speed of inference has also improved.
✔ After confirming the effectiveness of the Japanese version of ELECTRA, we decided to release the pre-trained language model to the public.
✔ In the future, we will build language models for each business or field, aiming to dramatically improve accuracy specific to the business.
For inquiries regarding this article or requests for business negotiations, please contactherePlease contact us from.
(Written by: Fujii)

