
technology


Hello. I am in charge of Cinnamon AI public relations.
Today, I would like to introduce the Japanese translation of the blog that introduces the contents of the internship "Boot Camp" that is regularly held at Cinnamon AI's Vietnam base.
This blog is operated by Cinnamon AI's Vietnam team, and a link to the blog is also posted at the end of this article. Please take a look.
Remember the boom in deep learning applications since the ImageNet contest?
Deep learning is now a milestone and fundamental approach for most machine learning tasks, including computer vision, natural language processing, and speech recognition. Until now, many AIs could only handle one content type, such as images or text. However, in order to approximate human behavior, we need an engine that combines these elements to handle multitasking problems. Examples of tasks that include both visual and textual content include text searches in images, image captions, and visual question answering. In this blog, I would like to introduce an overview of the VQA problem, challenges, and efforts toward practical application.
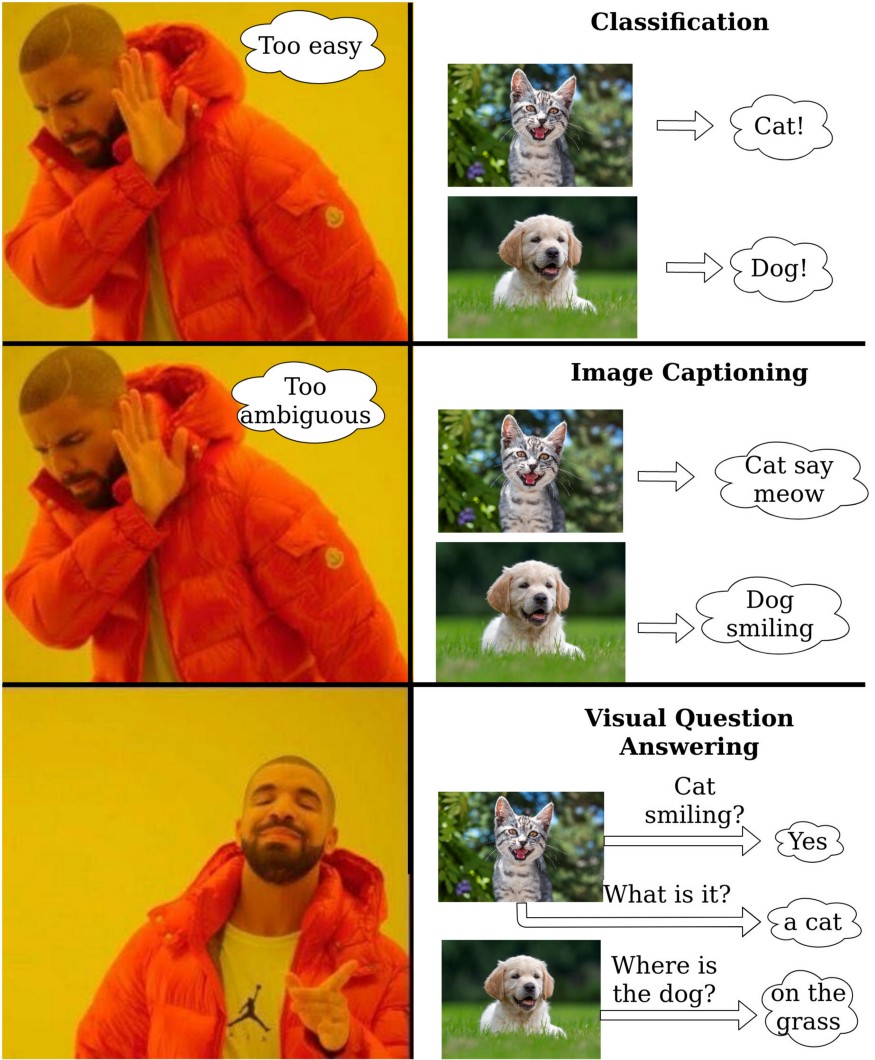
VQA stands for "Visual Question Answering"
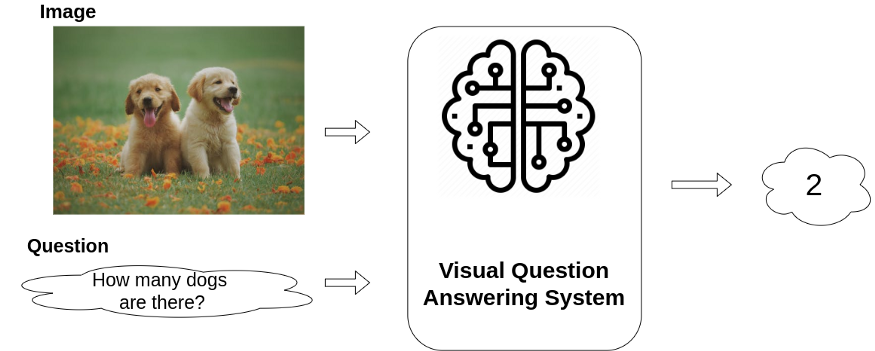 Figure 2: Illustration of a VQA System
Figure 2: Illustration of a VQA System
We define VQA here as the task of finding answers to questions related to a given image/video (visual content). Specifically, it takes visual content and related text-based questions as input, and outputs text-based answers. (Figure 2)
 Figure 3: Some examples of a VQA system's input
Figure 3: Some examples of a VQA system's input
With previous technology, it was said to be difficult to develop a VQA system that could answer arbitrary questions. However, this technology is now considered to be the core value of VQA systems. The questions are optional and cover many sub-questions in the field of computer vision. For example, look at Figure 4 and ask the following questions:
Q: Object recognition. What kind of food is there in the center?
Q: Object detection. Do you have meat?
Q: Classification of attributes. What color is an avocado?
Q: Counting numbers. How many types of food are there in total?
Q:…
 Figure 4: Arbitrary questions can be asked and some are related to a sub-problem in computer vision.
Figure 4: Arbitrary questions can be asked and some are related to a sub-problem in computer vision.
Additionally, more complex items require more advanced text comprehension, such as questions about spatial relationships between objects, events, actions, and common sense reasoning.
 Figure 5: Examples of some complex questions.
Figure 5: Examples of some complex questions.
In recent years, various algorithm development methods have been proposed. The common structure in algorithms consists of three main parts: visual information extraction, textual information extraction, and an algorithm that integrates these two features to generate an answer. The process of answer generation is usually thought of as a discriminant problem, where each unique answer is treated as a separate category. The main difference between the methods is how they combine visual and textual features.
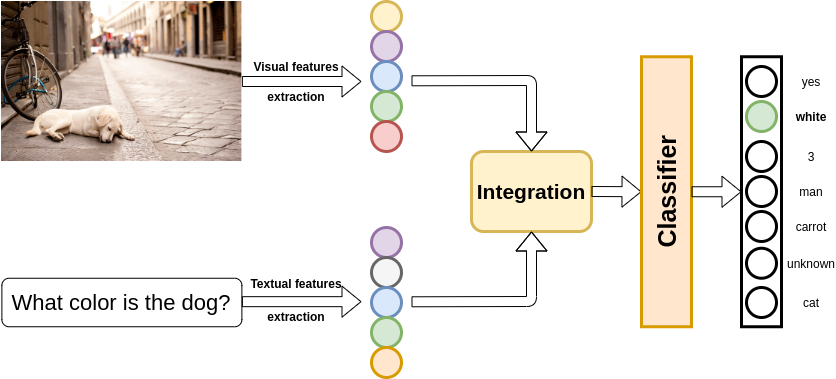 Figure 6: The flow of a VQA system.
Figure 6: The flow of a VQA system.
Since 2014, various studies have been conducted in the development of VQA systems that have faced numerous issues. The main issues discovered are listed below.
① Expertise
First of all, many challenges come from the prerequisite knowledge for system development. After all, ``vision'' is in the realm of computer vision in the past, and ``question answering'' is a problem of natural language understanding.That's why I think it's a good challenge.
② Lack of semantic consistency between image and text
A VQA system consists of two different data streams (textual data and visual data), which must be used and combined correctly to ensure robust performance. Therefore, to learn cross-modal representations, current state-of-the-art techniques on the VQA-v2 dataset use large-scale models to pre-train a large number of visual-text pairs.
③Limited answers – Not as free as thinking.
Most VQA algorithms view the process of generating an answer as a classification problem. An answer dictionary typically contains a pool of K possible answers, with some algorithm calculating the probability of each answer for a given question. The generated answers can be made more diverse as K increases, but this requires a larger model and a larger training dataset.
ability to answer complex questions
Machines have limited technological capabilities to develop like humans, and they still have a long way to go to catch up to human cognitive abilities. Complex questions such as "Why?" and questions that require advanced knowledge (e.g. Q. Who is the person in the photo? - A. Donald Trump) are typical examples of high difficulty. This is an example.
 Figure 8: An example of a hard question: To acknowledge the position of “global optimum for non-convex function” requires a (potentially) very vast knowledge base! (that human may not reach yet)
Figure 8: An example of a hard question: To acknowledge the position of “global optimum for non-convex function” requires a (potentially) very vast knowledge base! (that human may not reach yet)
The appeal of VQA lies in its relevance to our daily lives. Questions and answers are an important part of life and that will always be the case. The way VQA systems answer questions consists of understanding visual and textual information, and in some respects how to combine the two data streams and how to use advanced knowledge appropriately. Their decision making methods are similar to ours.
We present a range of potential applications integrating VQA systems. Currently, the best application is a free application provided by Microsoft that is being put into practical use to help visually impaired people. (Seeing AI 2016 Prototype – Microsoft Research Project) Many applications with visual and textual information conversion have been published and have improved the lives of many people.
Another application for VQA systems is human-computer interaction. Specifically, it is an application that provides for obtaining visual content. For example, kids can ask the system various questions to learn the names of real objects while looking at them, or ask the camera questions about the weather outside when they are indoors. .
This is an overview of the VQA issue. You can try VQA's online demo here. In the next article, we will review other approaches we have studied and our suggestions for improving VQA systems. Please stay tuned.
References
Answering visual questions. Datasets, algorithms, and future challenges
In this article, we have delivered a Japanese translation of the TECHBLOG that introduces the contents of the internship conducted at Cinnamon AI's Vietnam base. We would be happy if you could learn more about overseas human resources and AI research that Cinnamon AI is focusing on.
The English version of this article ishereYou can view it from here.
Translated with www.DeepL.com/Translator (free version).
For inquiries regarding this article or product consultation, please contactherePlease send it from
Also, Cinnamon AI regularlyHolding a seminarDoing.

