
経営



昨年のダボス会議で日本政府が提言した「DFFT(Data Free Flow with Trust)」。これはSociety5.0の実現に向け、信頼性を担保した上でデータをもっと自由に流通させるべきであるという基本概念のことです。
先行するヨーロッパでは、すでにGDPR(一般データ保護規則)というポリシーを設け、個人データの管理保護と活用を推進していますが、日本もこれに追随し、スマート社会への移行に向けて着々と歩みを進めているわけです。
AIを有効活用するためには当然、元になるデータが必要です。つまり、これからいっそうAIが社会に組み込まれていく中で、データは大切な競争力の源泉となります。ところが、とりわけ個人情報にひもづくデータは、そもそもオープンな場に集められているものではなく、また、活用を前提とした管理をされていません。
そこで、AIを有効かつ安全に利用できるAI-Readyな状態を作ろうというのが、DFFTの根底にある考え方です。
しかし、個人情報の開示にアレルギー意識の強い日本では、データの自由な流通に反発する意見も多いのが現実です。そこにはセキュリティ面への不安も多分にあるでしょう。
そこで最初から大掛かりなAIモデルの構築を目指すのではなく、局所的にデータを活用するスモールAIのモデルを作っていくべきというアイデアがあります。
スモールAIとは何か。これは例えば、ある中学校のあるクラスの中だけで稼働する学習モデルや、特定の病院やECサービス内のみで稼働する学習モデルを差しています。世の中で汎用的に使えるデータが整備されていない以上、まずはそうした局所的なAIを大量に作っていくことから始めよう、というわけです。
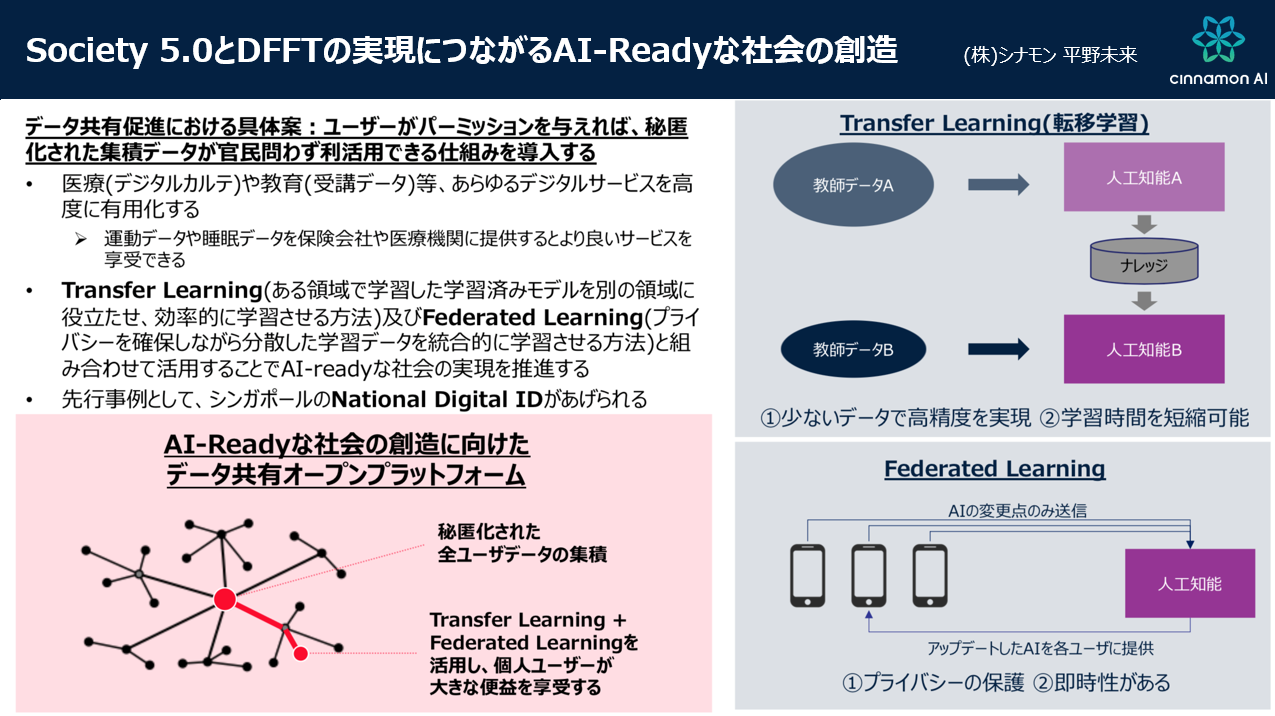
とはいえ、このスモールAIのモデルを構築するにしても、ユーザーの同意を得るためには様々な障壁があるでしょう。そこで今回はFederated Learning とTransfer Learning、2つの手法について考えてみたいと思います。
 *内閣官房IT総合戦略本部・会議提出資料
*内閣官房IT総合戦略本部・会議提出資料
まずFederated Learningとは、プライバシーを確保しながら分散した学習データを統合的に学習させる⽅法のこと。最も身近なサンプルとしては、スマートフォンに実装されているグーグルの仮想キーボードアプリ、「Gboard」が好例でしょう。
「Gboard」は文字盤をなぞるようにして使える「グライド入力」に対応するなど、文字入力の面で高い利便性を発揮する多言語キーボードアプリで、私自身も日頃から大いに活用しています。その本領は実は文字入力ではなく、背景でAIが稼働している点にあります。
「Gboard」はグーグルのクラウドと連携し、個々のユーザーの変換特性や使用頻度の高い単語などをそのつど学習しているのです。そのため、使えば使うほどそのユーザーの個性に合わせてカスタマイズされるのが大きな特徴。
これこそ、スマホ1台単位のスモールAIであり、個別のスマホ端末で学習したデータはクラウド上で統合され、各端末にフィードバックされるというFederated Learningのモデルなのです。
ここで重要なのは、クラウドに上がるデータはあくまで活用の傾向のみであり、入力した単語や内容はもちろん、ユーザーの個人情報には一切触れていない点です。情報はあくまで秘匿化され、それが中枢で集積されるこのモデルは、個人情報保護に敏感な日本人にとっても受け入れやすい手法と言えるでしょう。
一方、Transfer Learningとは転移学習の意で、ある領域における学習済みモデルを別の領域に転用し、効率的に学習させる⽅法を意味しています。
AIは本来、医療に活用する場合は医療用のデータを、教育に活用する場合は教育用のデータを、それぞれ大量に必要としています。しかし、そのデータをどのように調達するかがひとつの障壁。そこでTransfer Learningの手法では、医療用のデータをカスタマイズして教育モデルに転用し、限られたデータで効率的な学習が可能になります。
例えば弊社が提供するサービスのように、免許証などからOCRで読み取った住所・氏名などの情報を、そのまま請求書の差出人欄に転用するモデルがわかりやすい事例でしょう 。免許証を読み込むAIと請求書を読み込むAIを個別に開発するよりも、ひとつのデータを使い回すほうが効率的であるのは言わずもがなです。
このTransfer Learningの手法を応用すると、学校内で数学の試験データを国語の科目に転用したり、あるいは在校生データを街の医療機関に転用したり、セントラルサーバを介して利便性は多方面に広がっていくことになります。
シンガポールでは実際に、ユーザーがパーミッションを与えることで、National Digital IDの活用が進められ、行政サービスの提供をより手軽なものにしています。行く行くは、スマートウォッチから収集された生体データが、クラウドを介して医療機関に転用され、より適切な診療が受けられたり、保険会社からより適切な商品のレコメンドが受けられたりする時代がやって来るかもしれません。技術的には今でも十分に実現可能です。
さらに進めば、ECサイトと個人の与信がひもづいて、欲しいものを購入する際、必要な金額をその場で借り入れられるようなことも可能になるでしょう。集積データが官民問わず活用できるようになれば、アイデア次第で社会の利便性は格段に上がっていくはずです。

ただし、いずれのケースでもカギを握るのは、データ流通に対する信頼性です。ユーザー側がデータ提供することを信頼し、パーミッションを与えなければ、せっかく存在している集積データを活用できず、持ち腐れてしまうことになります。これではスマート社会の実現など夢のまた夢。
これを解決するのはテクノロジーで、ことプライバシーの問題に関して言えば、先述したFederated Learningのモデルでほぼ解決は可能であると考えられます。政府が打ち出したDFFTの概念の下、その有用性をどこまで国民に周知できるかが今後の課題でしょう。
IoTを駆使することによって、サイバー空間とフィジカル空間の理想的な連携を目指すSociety5.0。それによって実現するスマート社会では、私たちの暮らしはどのように変化するのでしょうか。
例えば企業を訪ねた際に、これまでのように受付で手続きを行なうことなく、目的のフロアに直接アクセスできるようになるかもしれません。あるいは、アパレルショップに入店した瞬間、目の前のディスプレイに自分の欲しい物が次々に表示されるようなサービスが実現するかもしれません。
そんな世界に通じるAI-Readyな社会を創ることが、Society5.0への第一歩なのです。
 シナモンAI 代表取締役社長CEO 平野未来シリアル・アントレプレナー。東京大学大学院修了。レコメンデーションエンジン、複雑ネットワーク、クラスタリング等の研究に従事。2005年、2006年にはIPA未踏ソフトウェア創造事業に2度採択された。在学中にネイキッドテクノロジーを創業。IOS/ANDROID/ガラケーでアプリを開発できるミドルウェアを開発・運営。2011年に同社をミクシィに売却。ST.GALLEN SYMPOSIUM LEADERS OF TOMORROW、FORBES JAPAN「起業家ランキング2020」BEST10、ウーマン・オブ・ザ・イヤー2019 イノベーティブ起業家賞、VEUVE CLICQUOT BUSINESS WOMAN AWARD 2019 NEW GENERATION AWARDなど、国内外の様々な賞を受賞。また、AWS SUMMIT 2019 基調講演、ミルケン・インスティテュートジャパン・シンポジウム、第45回日本・ASEAN経営者会議、ブルームバーグTHE YEAR AHEAD サミット2019などへ登壇。2020年より内閣官房IT戦略室本部員および内閣府税制調査会特別委員に就任。2021年より内閣府経済財政諮問会議専門委員に就任。プライベートでは2児の母。 シナモンAI 代表取締役社長CEO 平野未来シリアル・アントレプレナー。東京大学大学院修了。レコメンデーションエンジン、複雑ネットワーク、クラスタリング等の研究に従事。2005年、2006年にはIPA未踏ソフトウェア創造事業に2度採択された。在学中にネイキッドテクノロジーを創業。IOS/ANDROID/ガラケーでアプリを開発できるミドルウェアを開発・運営。2011年に同社をミクシィに売却。ST.GALLEN SYMPOSIUM LEADERS OF TOMORROW、FORBES JAPAN「起業家ランキング2020」BEST10、ウーマン・オブ・ザ・イヤー2019 イノベーティブ起業家賞、VEUVE CLICQUOT BUSINESS WOMAN AWARD 2019 NEW GENERATION AWARDなど、国内外の様々な賞を受賞。また、AWS SUMMIT 2019 基調講演、ミルケン・インスティテュートジャパン・シンポジウム、第45回日本・ASEAN経営者会議、ブルームバーグTHE YEAR AHEAD サミット2019などへ登壇。2020年より内閣官房IT戦略室本部員および内閣府税制調査会特別委員に就任。2021年より内閣府経済財政諮問会議専門委員に就任。プライベートでは2児の母。 |
シナモンAIでは、コンサルティング、ワークショップ、ソリューションの提供を通じて、「AIを競争戦略に結びつける」お手伝いをさせていただいております。ぜひお気軽にお声がけをいただけましたら幸いです。
お問い合わせはこちら => お問い合わせフォーム
