
技術


前回の記事「Document Object Detectionについて」で記述した通り、Document Object Detection(書類オブジェクト認識)の手順を終えた後には、書類内におけるテキスト行の位置とテキスト内容を得ることができます。システムの目標は、契約書、医療明細書、生物学的なグラフ資料など、あらゆるタイプの事務書類に対応した情報抽出プロセスを提供することにありますが、この記事では、それがどのように達成されるかについて説明していきます。
まず、請求書/領収書を読み取るケースについて考えてみましょう。読み取りのためには、事前定義された5つのカテゴリに属するテキスト行を発見できるモデルが必要となります。
事前定義されたカテゴリに分類することが可能なモデルの作成について、カテゴリは以下の5つに分かれています。
通常、構成要素(テキスト行)があるカテゴリに属するかどうかを人間が判断する場合、位置情報とテキスト情報の両方が考慮されるはずです。したがって、私たちは空間情報とテキスト情報の両方を考慮した上で、モデルを見つける必要があります。
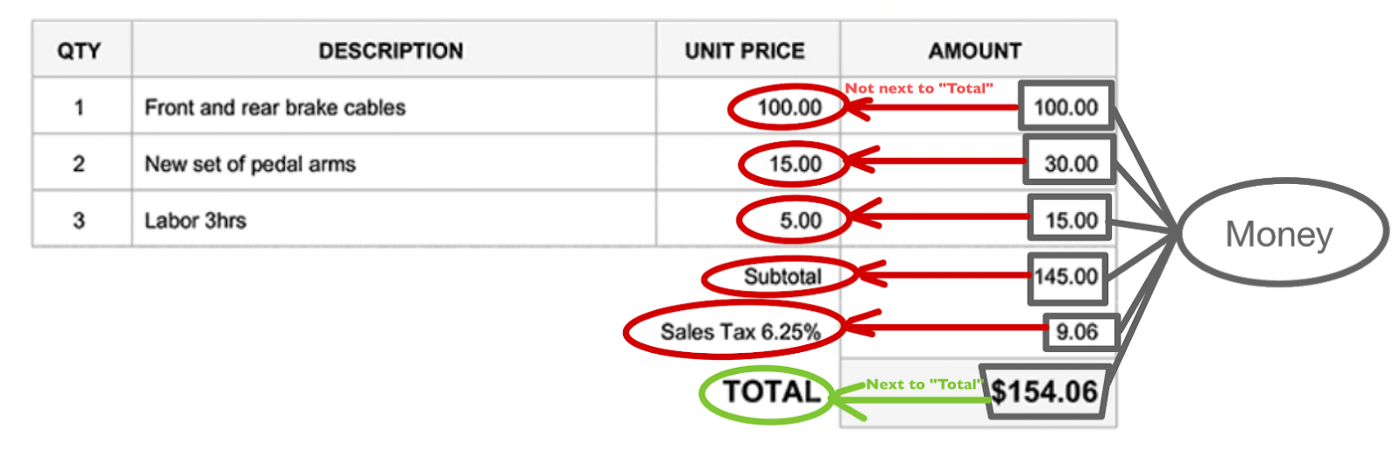
※請求書内のそれぞれの値は、近隣ノードに大きく依存している場合があります。
1つの解決策としては、セグメンテーションベースのアーキテクチャ(UNET、Deeplab,、Mask RCNNなど)を選定し、ピクセルベースのラベル付けに利用することが考えられます。弊社のチームからは「MSAU(Multi-Stage Attentional U-Net)」を提案しましたが、このモデルは上述の特性を用い、目標達成を支援してくれるものの、データの制限のために、さまざまなシナリオに対する頑健性*が不十分です。
MSAUは優れていますが、情報をコンパクトに保ちながら、まばらに分布するキーを検出するには、Graph(グラフ)の方が適しています。例えば、キー(仮に「合計」としましょう)と値(「10ドル」としましょう)が互いに離れすぎている場合でも、テキスト行が正確に抽出されていれば、グラフは比較的うまく処理することができます。
この記事では、主に使用されているコンポーネントであるグラフベースのキー・バリュー(Key-Value)検出器に焦点を合わせることにします。なぜなら、Flaxのパイプラインを説明するのに必要不可欠なコンポーネントだからです。
頑健性*・・・ある系が応力や環境の変化といった外乱の影響によって変化することを阻止する内的な仕組み、または性質のこと。
データ収集の制限と、頑健なモデルの必要性から、私たちはこの最新の問題において、より古典的ながらもコンパクトな表現である「グラフ」を領収書に向けて用いることにします。
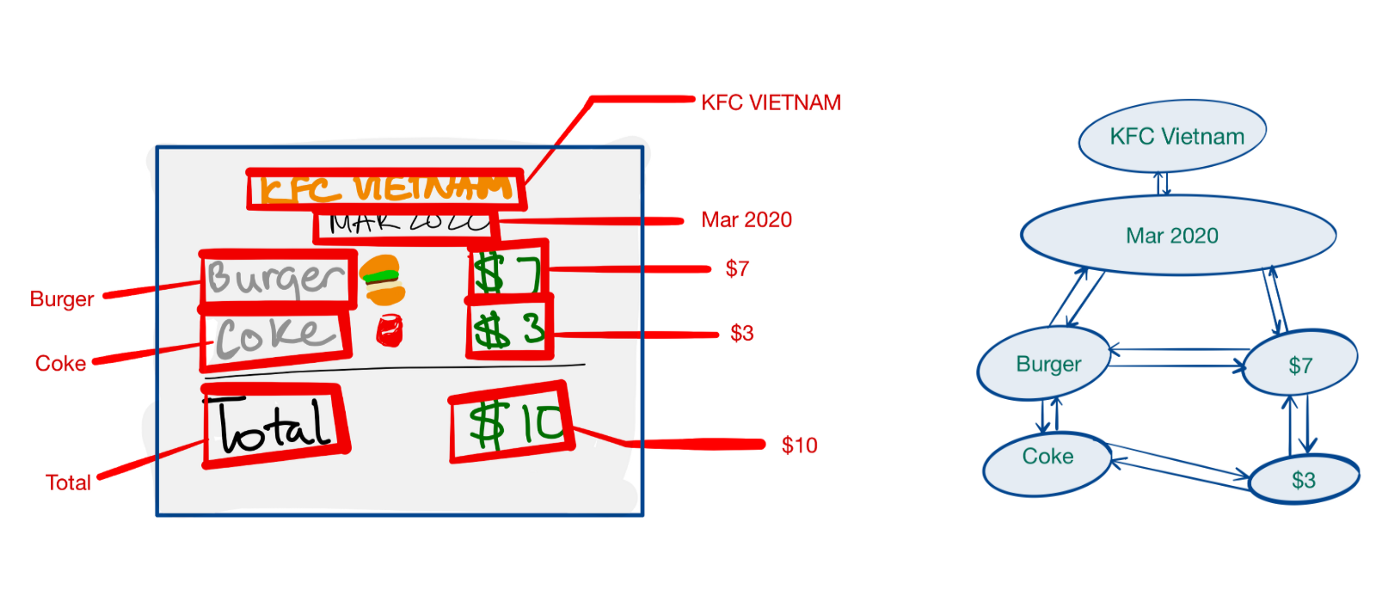
<領収書のグラフ表現>
グラフを利用することで、以下が実現します。
Layout Detection(レイアウト検出)とOCRの出力を用いることで、以下のような性質のグラフを構築することができます。
各ノードのクラスは近隣ノードに大きく依存します。
例えば、「10ドル」が「合計」のすぐ隣に現れた場合、それは領収書の合計金額を表しているはずです。それに対し、「コーラ」や「ハンバーガー」の隣に位置している場合は、おそらく合計金額を意味してはいません。
ここが大事なポイントで、場所は重要な意味を持っているということです。
ノードを分類する際は、すべての隣接ノードを考慮する必要があります。ノードの分類時に場所を判断に含めたいと考えたため、私たちの手法では、グラフ畳み込みの実行時に隣接ノード全てを計算に入れることにしました。
下記の図は、その様子を示しています。
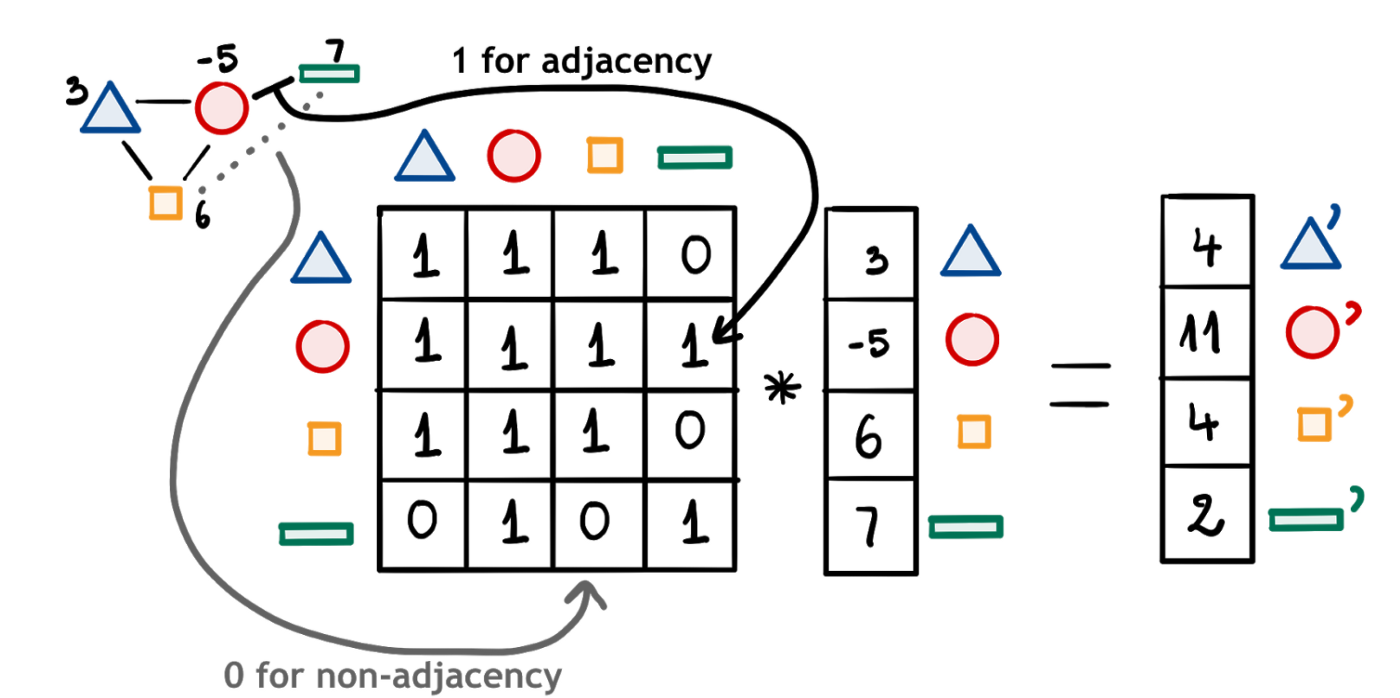
グラフの畳み込みが行列乗算によって実行されています。
これはグラフの畳み込みを表現するうえで、数学的にもコンピュータ的にも簡便な方法です。
以下に表示されているのは、GCNを利用したキー・バリュー抽出のデモです。さまざまなフィールドへカーソルを動かし、そのテキスト行に対応するクラス(緑の枠線部)や、その判断を説明する隣接ノード全て(赤の枠線部)を表示させています。判断の「説明可能性」の部分については、キー・バリュー抽出に関する別記事でご紹介する予定です。
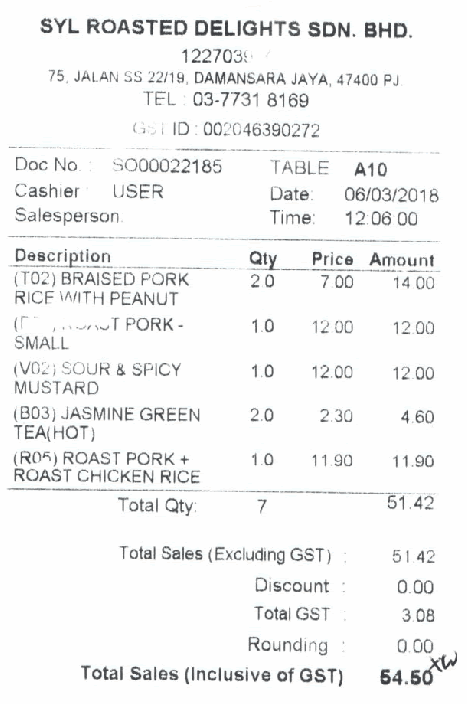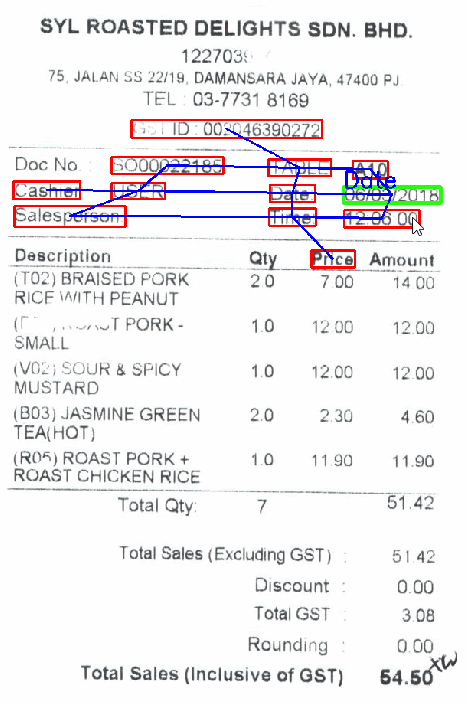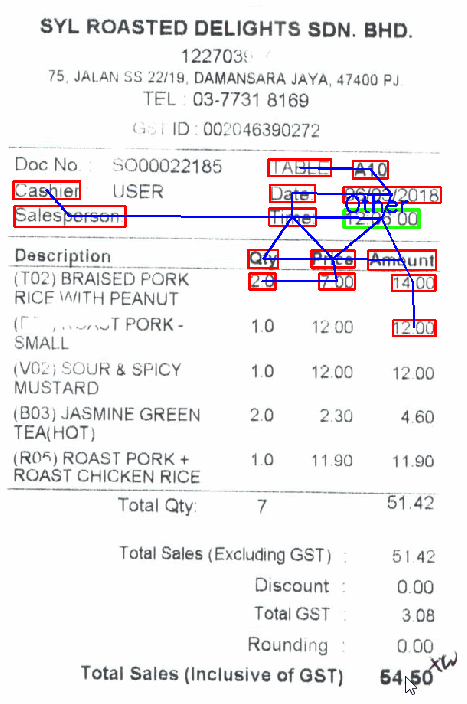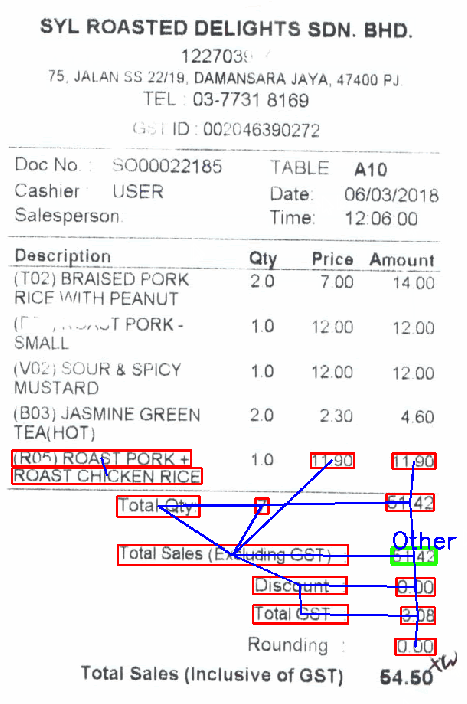
今回で1番重要だったポイントは、場所です。テキスト行のクラスは領収書内での位置と、テキスト行自体の「意味」によって決まります。そこで、グラフ畳み込みネットワークを用いれば、2つの情報を合わせて有効利用できるというわけです。
執筆:Patrick
コンサルタントチーム:Marc、Sonny、Toni
本記事に関するお問合せや、商談のご希望はこちらからご連絡くださいませ。
また、シナモンAIでは定期的にセミナーを実施しております。

