
技術


こんにちは。シナモンAI広報担当です。
シナモンAIでは自然言語処理技術を用いたプロダクトの Aurora Clipper(オーロラ・クリッパー)をご提供しており、特定の文脈を持つ日付(イベント開催日や契約日等)や人物名(契約者の関係)の取得、長い文章からの要点抽出、テキストの分類など様々な用途で用いられる製品です。
シナモンAIではグローバルでおよそ100名のAIリサーチャーを擁しており、その中でも自然言語処理に特化したチームではAurora Clipperの基礎となるAIモデルを日々改善しています。
本記事では、シナモンAIがこれまで取り組んできた自然言語処理に関する研究成果がAランクカンファレンスであるCIKM 2020に採択されましたので、シナモンAIのデリバリーマネージャーである藤井が概要をご紹介いたします。
こんにちは。シナモンAIの藤井です。
今回はAurora Clipperの機能の1つである情報抽出(Information Extraction)に関してご紹介いたします。
情報抽出機能では、様々な文書から必要な個所を自動的に抽出します。契約書や報告書の確認項目の抽出・要約を行うことができ、東芝エネルギーシステムズ株式会社様をはじめとして多くのお客さまにご利用頂いております。
さて、一般的に情報抽出のアルゴリズムを構築する際には多くのデータが必要となります。これは、同じ種類の項目の中から特定の役割を持つものだけを抽出するために文脈を利用するためです。例えば、イベント開催の文書から開催日を取り出したい場合、他の日付項目からイベント開催日を取り出すためには、その項目の文脈を利用することで初めて可能になります。
実際の情報抽出の研究でより利用されるデータセットととしてCoNLLがありますが、このデータセットには15,000件ものデータを学習データとして利用しています。
しかし、実際にビジネスで情報抽出アルゴリズムを構築する際に、15,000件のデータを集めることはコスト的にも期間的にも現実的ではありません。シナモンAIにて実施するAurora Clipperの導入プロジェクの多くは、学習データの数はおよそ50件~300件です。
研究成果として良い結果が出たアルゴリズムでも、その前提には大量のデータによる学習の結果である場合がほとんどです。そのため、アカデミックな研究成果はビジネスに転用されるまで非常に多くの時間とコストを必要としてきました。
さらに研究データの多くは英語で書かれており、最新アルゴリズムが提案されても日本語にローカライズされるまで多くの時間を要するため、日本語の情報抽出は世界的に遅れているのが現状です(最新アルゴリズムの日本語へのローカライズの工夫はこちら)。
シナモンAIではAurora Clipperを多くの企業に導入してきた経験から、少量データかつ日本語のデータで高い精度を達成するためのアルゴリズムの研究開発を行ってまいりました。
そして、その結果がCIKM 2020に”AURORA: An Information Extraction System of Domain-specific Business Documents with Limited Data“という論文が採択されましたので、今回ご紹介したいと思います!
まとめ①
✔ 情報抽出アルゴリズムの構築を行うには大量のデータ(約15,000件)が必要となるのが一般的
✔ その一方で、ビジネス利用を行うには大量のデータを用意することは現実的でない
✔ Aurora Clipperでは少量データで高い精度を達成するアルゴリズムを独自開発している
シナモンAIで構築したAURORAアルゴリズムの全体像を下図に記載しました。
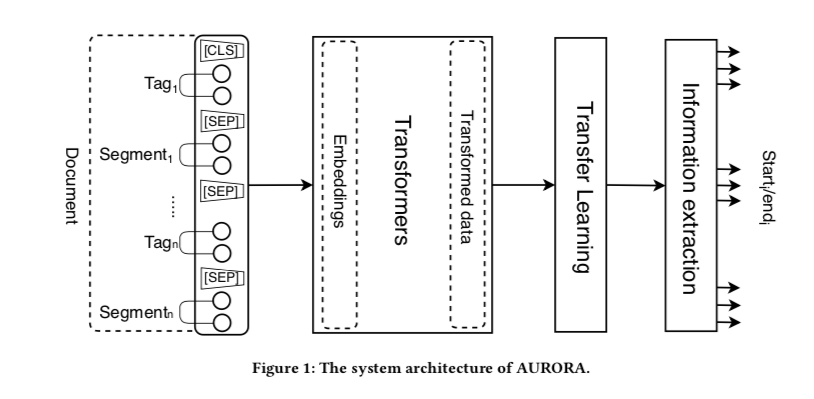
AURORAはまず最初にTAGとSEGMENTを含む入力文書を受け取ります。
TAGとSEGMENTは抽出対象項目とその値に対応しています。
例えば、契約書から契約日を抜き出す際には、TAGは”契約日”、SEGMENTは”2020/08/24″となります。
このTAGとSEGMENTのペアはTransformer層に供給され、隠れ層に変換・受け渡しが行われます。
その後、CNNで構成された層で不必要な情報を除去しつつ転移学習を行い、最終的にQuestion-Answeringタスクを利用した情報抽出モデルにより抽出対象項目を推論します。
大きな特徴としては、Transformer層に適用するアルゴリズムを複数選択できる構成となっている点です。
そのため、BERTだけでなくELECTRAやRoBERTAなど様々なアルゴリズムをTransformer層へ適用することができるようになります。
また、これらのTransformer層から得られた表現を利用し転移学習を行うことで、少量データから、高精度に非常に多くの種類の項目を同時に取り出すことを可能としています。
実際の実験結果は以下となります。
対象としてはシナモンAI内の研究データであるBidding docs(学習:77件、テスト22件)とSales docs(学習:300件、テスト:150件)を利用しました。
これらのデータは日本語で記載されており、情報抽出タスク用のデータとなっております。
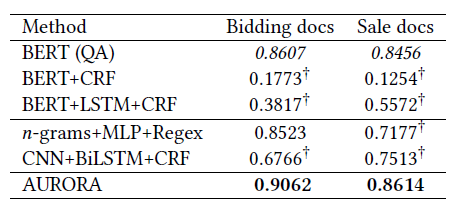
実際の結果としては、上表のようにAURORAモデルがBidding docs, Sale docs双方において精度評価指標であるF値において最も高いスコアとなりました。
対照実験としておいたBERT (QA) モデルは国内でも多くの自然言語処理プロダクトに適用されていますが、実際にビジネス利用を行うには、多くのデータを要する欠点をもっていました。
今回の研究では、AURORAモデルを利用することで、少量データでも高い精度が達成することができました。
今後はTransformer層の事前学習部分をより改善および業界特化し、AURORAモデルに組み込むことで、ニッチな業務でも早く高精度なモデルを提供できるように研究を進めて参ります。
まとめ②
✔ 転移学習を利用することで少量データで高精度を達成するAURORAモデルを提案
✔ AURORAモデルは、従来のBERTモデルより少量データの条件で高精度を達成
✔ 今後はAURORAモデルへ業界知識を埋め込み、業界特化型のモデルを構築予定
本記事に関するお問合せや、商談のご希望はこちらからご連絡ください。
また、シナモンAIでは定期的にセミナーを開催しております。
こちらより是非お申込みくださいませ。

