
技術


こんにちは。シナモンAI広報担当です。
シナモンAIでは自然言語処理技術を用いたプロダクトAurora Clipper(オーロラ・クリッパー)を展開しており、特定の文脈を持つ日付や人物名の取得、長い文章からの要点抽出、テキストの分類など様々な用途で用いられる製品を提供しております。
弊社では100名程度のAIリサーチャーを抱えており、その中でも自然言語処理に特化したチームではAurora Clipperの基礎となるAIモデルも日々改善しています。本記事では、自然言語処理技術に関わる研究の成果として日本語版ELECTRAを公開したため、弊社のPMが概要をご紹介いたします。
自然言語処理はその名の通り、言葉を数値情報として取り扱うことで、言葉の持つ意味を解析します。
この技術が特に注目されるようになったのは、Google Brainが2018年5月にBERT (Bidirectional Encoder Representations from Transformers) と呼ばれるアルゴリズムを提案したことがきっかけとなっており、この技術により既存の自然言語処理タスクの精度が飛躍的に向上しました。
従来の自然言語処理ではテキスト分類や質疑応答など目的毎にニューラルネットワークを構築していましたが、BERTではWikipediaなどのラベルのない大量の文章から事前学習した言語モデルを転移学習させることで、様々なタスクが汎用的に実行できるようになりました。その結果、大量のラベル付きデータがなくても、非常に精度の高い自然言語処理が行えるようになりました。BERTを利用したチャットボットがビジネス現場で実用化されるなど、実業務でも利用されるケースが増えてきました。
BERTの登場以降、XLNetやRoBERTaなど、BERTをベースとしたモデルが多く提案されましたが、1つ大きな問題がありました。それは、言語モデルの学習に時間がかかるという点です。言語モデルを自ら構築するとなると、GPU1台のみを利用した場合、数か月かかるのが現状です。そのため、日本語に特化した言語モデルの構築には多くの時間を要し、現在は一般公開されているWikipediaの日本語文書を事前学習させたBERT向け言語モデルが汎用的に利用されています。
その一方で、WikiPediaのデータで学習させたBERT向け言語モデルは製造業界や保険業界など、特殊な用語が頻出する業界においては、まだまだ精度が出辛いのも現状です。しかし、業界特化の言語モデルを構築するには費用と時間がかかる上に精度の向上度合いの確証も得られないこともあり、業界特化のBERTモデルを構築する投資判断が下され辛い現状もあります。
まとめ①
✔ 自然言語処理はBERTを起点として急激に進歩している
✔ その一方で、言語モデルの学習には多くの時間を要し、また、日本語に対応しているBERTでは、一般的なコーパスであるWikipediaベースのものが多い
✔ そのため、特別なドメインに依存した用語を用いる業務に対しては十分な言語分析性能がない場合があるため、業界特化の言語モデルの構築が必要だが投資判断が下されにくい
ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)は2020年5月にGoogle Brainから2020年5月に人工知能のトップカンファレンスであるICLR (The International Conference on Learning Representations) にて発表されたBERTの後継となるアルゴリズムです。
ELECTRAは、これまで画像認識の分野で利用されてきたGAN (敵対的生成ネットワーク:Generative Adversarial Network)のアイデアを、言語モデルの学習に適用したものとなります。

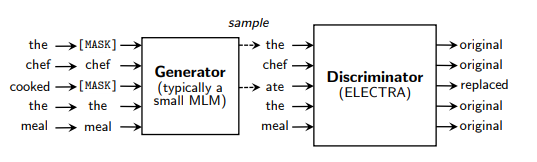 ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS (ICLR 2020) より引用
ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS (ICLR 2020) より引用
大きな特徴としては、BERTの後継であるRoBERTaと比較しても、学習量が約1/4と少ないデータで同等の精度が達成ができます。また、推論の処理も高速で実行することができるのが主な特徴です。
しかし、Google Brainから公開された言語モデルは英語版のWikipediaおよびWebサイトを利用して構築したものとなっており、日本語に対してどのような効果を発揮するかは未確認でした。そのため、弊社では研究活動の一環として、日本語版のWikipediaを利用し、日本語に特化したELECTRAの言語モデルを構築しました。その結果、これまで弊社で実施してきたプロジェクトのデータでもBERTと比較し、精度(F値)が3~20%上昇する結果が得られました。また、事前学習で用いた12GBのWikipediaデータをGPU1本の条件において、約5日間で完了することができ、推論もCPUのみでBERTの約1/4の速度で実施できることが確認できました。
これまでのBERTの推論においては、非常に時間がかかり、弊社のようなオンプレミスでAIを導入する会社にとっては、GPUをお客様に導入して頂くことが必要不可欠であると同時に、導入の大きな壁となっていました。そのため、CPUで推論ができるELECTRAはオンプレミスにおけるAI導入の障壁を大きく下げることができると期待しています。
ELECTRAは、上記のような素晴らしい結果をもたらしてくれましたので、日本における自然言語処理をより促進すべく、日本語版ELECTRAを一般公開することに決定いたしました。
https://huggingface.co/Cinnamon/electra-small-japanese-generator
https://huggingface.co/Cinnamon/electra-small-japanese-discriminator
これにより、弊社だけでなく、日本全体において、自然言語処理を利用したビジネスAIの利用が促進されればと思います!
今後、弊社では業界別やお客様別に特化した言語モデルの構築及び、お客様環境にあった知識体系の構築により、ドメイン知識を獲得し、高い精度のビジネスAIの提供を進めていきます。
また、最先端の研究を日本語にローカライズし、よりお客さまが業務効率化を感じてい頂けるよう努力して参ります!
✔ 日本語版ELECTRAを構築することで、過去プロジェクトの精度が向上し、かつ推論の速度も向上した
✔ 日本語版ELECTRAの有効性が確認できたため、事前学習した言語モデルを一般公開することにした
✔ 今後は業務別あるいは分野別の言語モデルを構築し、業務に特化した飛躍的精度向上を目指す。
本記事に関するお問合せや、商談のご希望はこちらからご連絡くださいませ。
(文責:藤井)

