
技術


こんにちは。シナモンAI広報担当です。
本日は、シナモンAIベトナム拠点で定期的に実施されているインターンシップ「Boot Canp」内で実施されている内容を紹介しているブログの日本語訳版をご紹介したいと思います。
本ブログはシナモンAIのベトナムチームにより運営されており、本記事の最後にブログへのリンクも掲載しています。是非ご覧ください。
ImageNetコンテスト以来、ディープラーニングアプリケーションがブームになったことを覚えていますでしょうか?
今やディープラーニングはコンピュータビジョン、自然言語処理、音声認識など、ほとんどの機械学習タスクのマイルストーンであり、基本的なアプローチとなっていると言えます。これまでの多くのAIは、画像やテキストなどの1つのコンテンツタイプしか扱えませんでした。しかし、人間の行動に近づけるためには、それらの要素を組み合わせて、マルチタスクの問題を処理するエンジンが必要になります。ビジュアルコンテンツとテキストコンテンツの両方を含む作業の例としては、画像内のテキスト検索、画像キャプション、視覚的な質問応答などがあります。今回のブログでは、VQA問題の概要、課題、実用化に向けた取り組みについてご紹介したいとおもいます。
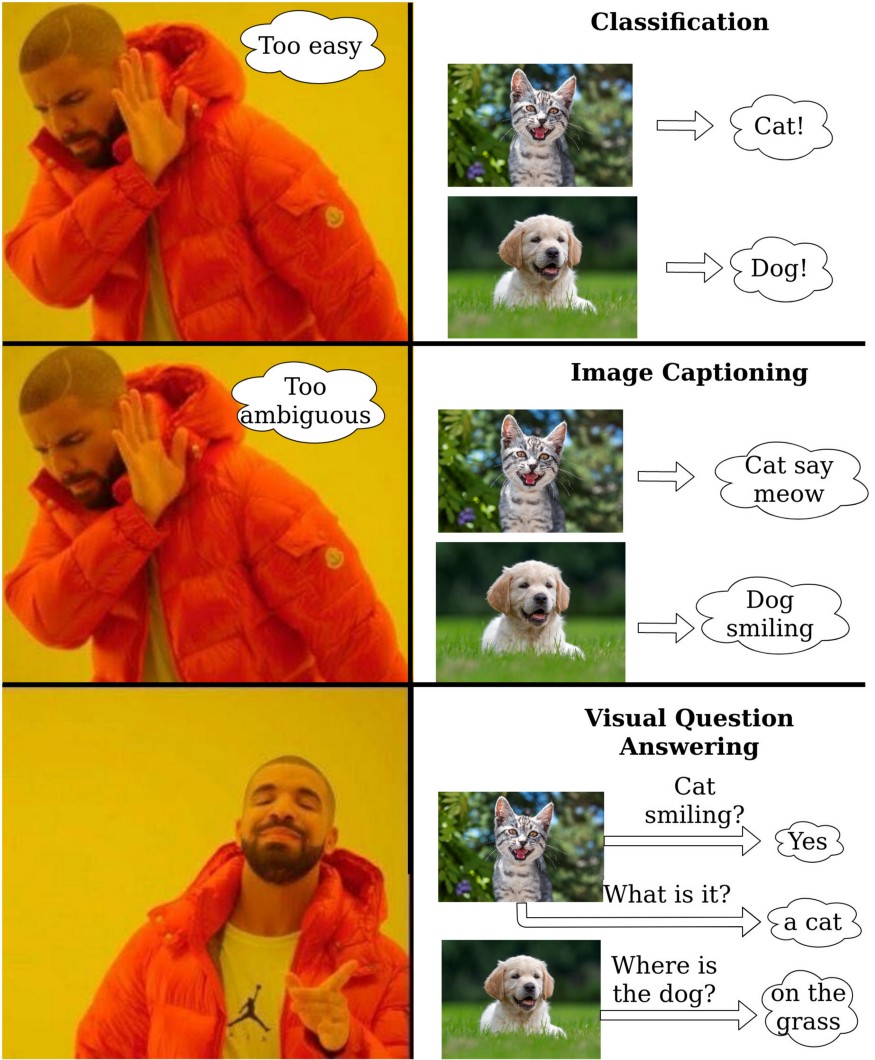
VQAは「Visual Question Answering」の略です
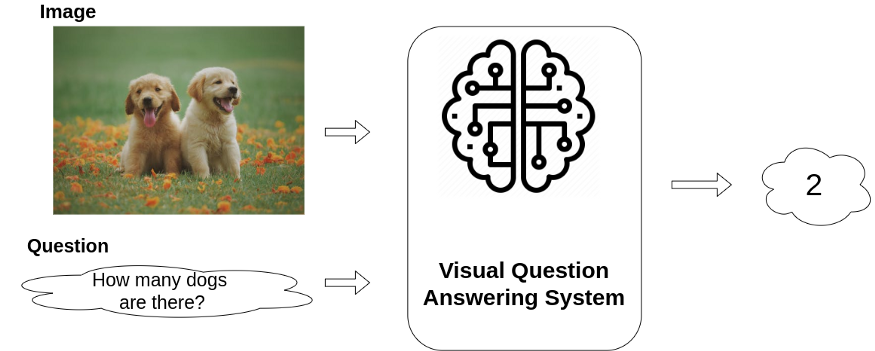 Figure 2: Illustration of a VQA System
Figure 2: Illustration of a VQA System
与えられた画像/動画(ビジュアルコンテンツ)に関連する質問に対する答えを見つける作業をここではVQAと定義します。具体的にどのようなものかというと、ビジュアルコンテンツとそれに関連したテキストベースの質問を入力とし、テキストベースの回答を出力します。(図2)
 Figure 3: Some examples of a VQA system’s input
Figure 3: Some examples of a VQA system’s input
以前の技術では、任意の質問に答えられるVQAシステムの開発は、難しいと言われていました。しかし現在では、この技術がVQAシステムの中核的な価値であると考えられています。質問は任意のものであり、コンピュータビジョンの分野では多くの部分問題を網羅しています。例えば、図4を見て、以下の質問を見てみましょう。
Q:物体の認識。中央にはどんな食べ物がありますか?
Q :物体の検出。肉はありますか?
Q:属性の分類。アボカドの色はどんな色ですか?
Q:数のカウント。食べ物は全部で何種類ありますか?
Q:…
 Figure 4: Arbitrary questions can be asked and some are related to a sub-problem in computer vision.
Figure 4: Arbitrary questions can be asked and some are related to a sub-problem in computer vision.
さらに、より複雑なものだと、対象物、出来事、行動、常識的な推論の間の空間的な関係についての質問など、より高度なテキスト理解が必要となります。
 Figure 5: Examples of some complex questions.
Figure 5: Examples of some complex questions.
近年、さまざまなアルゴリズムの開発手法が提案されています。アルゴリズムにおいての共通の構造は、視覚的な情報の抽出、テキスト情報の抽出、およびこれら2つの特徴を統合して解答を生成するアルゴリズムの3つの主要部分から構成されています。解答生成のプロセスは通常、判別問題として考えられており、それぞれのユニークな回答は別個のカテゴリとして扱われます。手法の主な違いは、視覚的特徴とテキスト的特徴をどのように組み合わせるかという点です。
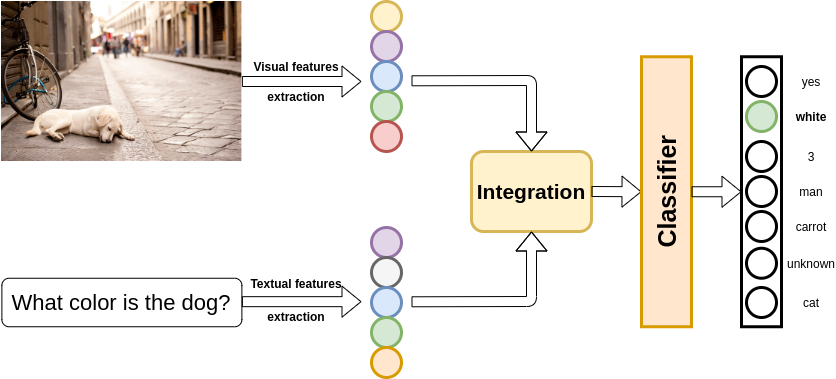 Figure 6: The flow of a VQA system.
Figure 6: The flow of a VQA system.
2014年以降数々の課題を抱えたVQAシステムの開発において、様々な研究が行われてきました。主に発見された課題を以下に記載します。
①専門性
まず第一に、数々の課題はシステム開発のための前提知識から来ています 。結局のところ、「視覚」は過去のコンピュータビジョンの領域にあり、「質問応答」は自然言語理解の問題なのです だからこそ、課題に対しては良いチャレンジになると考えています。
②画像とテキストの意味的な整合性の欠如
VQAシステムは、2つの異なるデータストリーム(テキストデータとビジュアルデータ)で構成されており、堅牢な性能を確保するためには、それらを正しく使用し、組み合わせる必要があります。そのため、クロスモーダル表現を学習するために、現在のVQA-v2データセットの最新技術では、大規模モデルを使用して多数の視覚・テキストペアを事前学習しています。
③限られた回答 – 思考のように自由自在ではない。
ほとんどのVQAアルゴリズムは、回答を生成するプロセスを分類問題として捉えています。回答辞書には通常、K個の可能な回答のプールが含まれ、与えられた質問に対する各回答の確率が何らかのアルゴリズムによって計算されています。生成された答えは、Kが増加するにつれて、より多様なものにすることができますが、そのためには、より大きなモデルとより大きな学習データセットが必要になります。
複雑な質問に答える能力
機械は人間のように発達する技術的能力は制限されており、人間の認知能力に追いつくにはまだ長い道のりの半ばです。”なぜ?”などの複雑な質問や、高度な知識を必要とする質問(例:Q.写真の中の人物は誰ですか? ーA.ドナルド・トランプ氏です)などは難易度の高い典型的な例です。
 Figure 8: An example of a hard question: To acknowledge the position of “global optimum for non-convex function” requires a (potentially) very vast knowledge base! (that human may not reach yet)
Figure 8: An example of a hard question: To acknowledge the position of “global optimum for non-convex function” requires a (potentially) very vast knowledge base! (that human may not reach yet)
VQAの魅力は、私たちの日常生活との関連性にあります。質問と回答は生活の重要な部分であり、それは常に変わることはありません。VQAシステムが質問に答える方法は、視覚情報とテキスト情報の理解から構成されており、2つのデータストリームをどのように組み合わせるか、高度な知識をどうやって適切に使うか、といういくつかの点においては判断の方法が私たちと似ています。
VQAシステムを統合した一連の潜在的なアプリケーションをご紹介します。現在、最も優れているといわれているアプリケーションは、視覚障害者の支援で実用化されているマイクロソフトが提供する無料のアプリケーションです。(Seeing AI 2016 Prototype – マイクロソフトの研究プロジェクト)視覚とテキストの情報変換を備えた多くのアプリケーションが公開され、多くの人々の生活を改善してきました。
VQAシステムのもう一つの用途としては、人間とコンピュータのインタラクションが挙げられます。具体的には、視覚的なコンテンツを得るために提供されるアプリケーションです。例えば、子供がシステムに対して様々な質問をして、実際の物を見ながらその名前を学んだり、ほかにも、屋内にいるときに外の天気についてカメラに質問したりすることができます。
以上がVQA問題の概要です。ここではVQAのオンラインデモを試すことができます。次の記事では、私たちが研究した他のアプローチと、VQAシステムを改善するための私たちの提案をレビューします。ご期待ください。
参考文献
視覚的な質問への回答。データセット、アルゴリズム、将来の課題
本記事では、シナモンAIのベトナム拠点にて行っているインターンシップでの実施内容を紹介するTECHBLOGを日本語訳にてお届けいたしました。シナモンAIが注力しております海外人材やAIの研究について知っていただけますと幸いです。
本記事の英語版はこちらよりご覧いただけます。
www.DeepL.com/Translator(無料版)で翻訳しました。
本記事に関するお問合せや製品に関するご相談はこちらからお送りください。
また、シナモンAIでは定期的にセミナーを実施しております。

