
technology


Hello. I am in charge of public relations for Cinnamon AI.
Today, I would like to introduce the Japanese translation of the technical blog operated by Cinnamon AI Vietnam base. A link to the blog is also included at the end of this article. Please take a look.
First, let's think about documents. Office documents play an important role as tools for communicating, storing, and retrieving data.
In fact, such paperwork is generated when doctors create statements for patients and when clerks provide bills to customers, and is often used as an intermediate method before being stored in a digital database. is also used.
This type of information extraction (IE) from office documents will become a daily necessity for people in various positions such as doctors, customers, accountants, researchers, sales representatives, etc.
Due to the wide variety of users, we believe that IE requires a very high level of accuracy. Additionally, a certain level of expertise may be required to verify the extracted information.
Flax Scanner, built with Cinnamon, is designed to extract pertinent information from office documents such as those mentioned above.
Flax Scanner can read medical statements, invoices, insurance applications, etc. in an accurate and efficient manner.
Using a deep learning-based pipeline that will be introduced in a future article, Flax Scanner can be easily retrained from small amounts of annotated documents.
By building this product, we hope to increase the time that doctors and pharmacists can spend on learning and research. We also hope that back-office personnel will spend more time considering and utilizing digital data to improve overall productivity.
In this blog post series, we will be covering ourFlax ScannerWe will discuss each component of the system, its main performance, and the notable characteristics that we have developed.explainability” will be verified.
As we have seen, Flax has a wide range of users, and some use cases can require very high levels of accuracy.
This requires Flax to be able to handle the various formats and layouts mentioned above while maintaining a high level of precision for each format.
OurFlax ScannerThe entire system mainly consists of the following two types of modules.
Here, we will first discuss the above modules. We plan to introduce the other important component (Explainer) in the next installment.
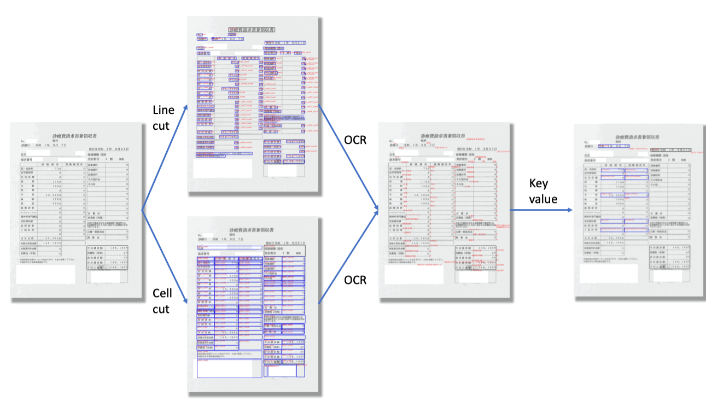
Engineers and researchers often ask, "Why do I need to first decompose a document image before performing information extraction (IE)?"
Certainly, applying object detection techniques like Faster RCNN [2] and YOLO [3] towards the whole structure is also attractive, but we do not adopt it.
We think it would be better to make Document Object Detection a general-purpose module that can handle any document. The reason behind this is that each document or format requires the extraction of unique fields, such as the name of a drug for a medical statement or the product price for an invoice.
Therefore, we need an intermediate representation that covers all of them.
After image decomposition, the task is to detect, locate, and recognize all useful information for further key-value extraction.
In our system, the layout sub-module handles the shape and position of each object, while the optical character recognition (OCR module) handles the position of text lines and the conversion of images to text content.
As mentioned immediately above, layout modules are used to locate intermediate components of a document, such as tables, imprints, and lines of text. This module takes image input and outputs the coordinates and dimensions of such components.
In real-world scenarios, document layouts vary in shape, size, image quality, and lighting conditions, making it difficult to normalize images to a specific intermediate format.

However, we have continued to improve it and have applied augmentation techniques as well as various features (distortion correction, contrast enhancement, orientation correction, etc.). The module realized through this process achieves high performance (IoU [Intersection over Union] of approximately 0.9) in detecting the main components such as text areas, seal impressions, and tables in document images even under a wide variety of lighting and background conditions. it's finished.
Next, the image of the text line is cropped using the position information obtained from the Layout module. This allows the OCR module to convert it to text data.
What I would like to mention here is that the development of OCR technology has a long history. Researchers have been trying to convert images to text using projection distributions and hand-crafted functions.
Cinnamon AI utilizes state-of-the-art deep learning architecture to achieve maximum performance and accuracy under a wide variety of conditions.
Not only do the lighting, shape, and font challenges mentioned above affect both layout and OCR, but for OCR to actually handle real-world use cases, it must also include handwritten text in addition to printed text. Must be able to handle it.


Over the past few years, researchers in the field of AI have developed a wide variety of neural network architectures that mimic the human brain to solve specific tasks. It is popular among networks for processing such image and text information, and can be used in our system.Convolutional Neural Network (CNN)andRecurrent Neural Network (RNN)there is. The following sections discuss each of these architectures in turn.
The input to Document Object Recognition (DOR) is an image, which is automatically converted into a set of feature maps using a CNN. Through convolutional layers, visual cues are aggregated into each feature map, and the final layer pulls out a mask representing the position of the text line. This article focuses only on the most common component of document images: lines of text. This process is called text line segmentation.
Among the specific architectures of convolutional networks, AR-UNET is an advanced one for segmentation tasks.
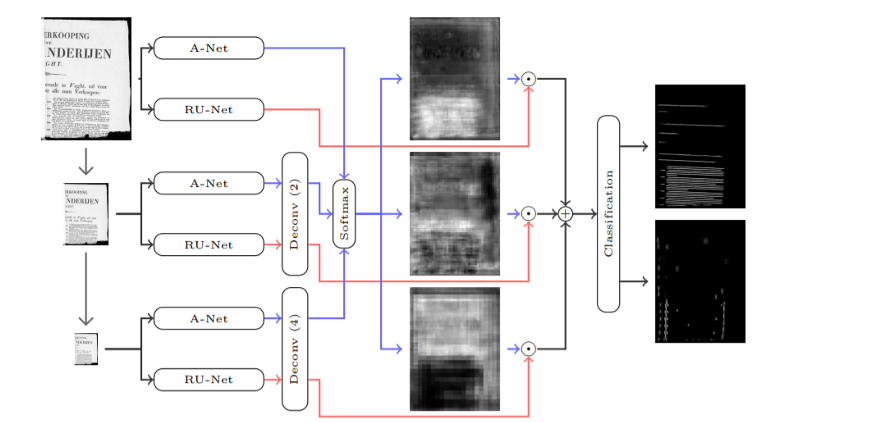
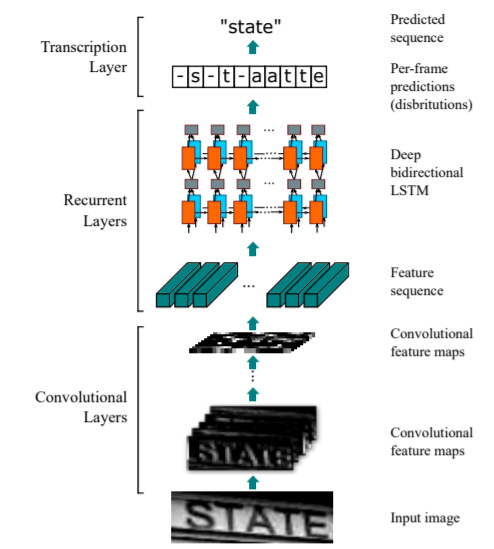
After applying segmentation (layout detection) to an image, you might expect to get the position of the text box, but what you're still getting is a feature map (which you can see as a large number of images). yeah. To convert it into a text representation, we need to perform an optical character recognition (OCR) process. This is where convolutional recurrent neural networks (CRNNs) come into play.
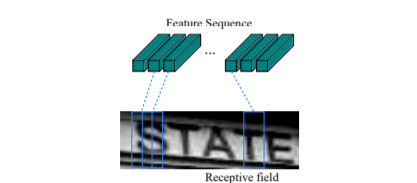
By sliding a rectangle that may contain a single character through the feature series and considering it, the RNN learns the relationships between the series both forward and backward. Masu. Finally, the character predictions are passed to the CTC probabilistic model. The model calculates confidence scores for all possible strings in a document image and then determines the final correct string. The entire flow of CRNN architecture is shown in the image below.
In this first article, we provided an overview of Flax Scanner. We also highlighted the challenges that solutions may face and discussed some of the promising solutions being used to address the Document Object Recognition component challenge. If you would like to learn more about other components and our systems, stay tuned for future articles.
[1] Grüning, T., Leifert, G., Strauß, T., Michael, J., & Labahn, R. (2018). A Two-Stage Method for Text Line Detection in Historical Documents. https://doi.org/10.1007/s10032-019-00332-1
[2]Ren, S., He, K., Girshick, R., & Sun, J. (2017). Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6), 1137–1149. https://doi.org/10.1109/TPAMI.2016.2577031
[3] Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2016-Decem, 779–788. https://doi.org/10.1109/CVPR.2016.91
The English version of this article ishereYou can view it from here.
For inquiries regarding this article or requests for business negotiations, please contactherePlease contact us from.
Also, Cinnamon AI regularlyHolding a seminarDoing.
(Written by: Morita)

