
technology


Previous article"About Document Object Detection"As described inDocument Object DetectionAfter completing these steps, you can obtain the position and text content of the text lines in your document. The goal of the system is to provide an information extraction process for all types of office documents, such as contracts, medical statements, biological graphs, etc., and this article describes how this is accomplished. I will explain about it.
First, let's consider the case of reading an invoice/receipt. For reading, we need a model that can discover lines of text that belong to five predefined categories.
Regarding the creation of models that can be classified into predefined categories, the categories are divided into the following five categories.
Normally, when humans decide whether a component (line of text) belongs to a certain category, both location and text information should be considered. Therefore, we need to find a model by considering both spatial and textual information.
*Each value in the bill may be highly dependent on neighboring nodes.
One solution is to choose a segmentation-based architecture (such as UNET, Deeplab, or Mask RCNN) and use it for pixel-based labeling. From our team, “MSAU (Multi-Stage Attentional U-Net)”, but although this model uses the characteristics mentioned above and helps us achieve our goals, it is not sufficiently robust* to various scenarios due to data limitations.
MSAU is great, but Graph is better for finding sparsely distributed keys while keeping the information compact. For example, if the key (let's say "sum") and value (let's say "10 dollars") are too far apart from each other, the graph can still handle it relatively well if the lines of text are extracted accurately. can.
In this article, we will focus on the main component used: graph-based key-value detectors. Because it is an essential component to explain the Flax pipeline.
Robustness*: An internal mechanism or property that prevents a system from changing due to external disturbances such as stress or changes in the environment.
Due to data collection limitations and the need for a robust model, we choose to use a more classical but compact representation for receipts in this current problem: a graph.
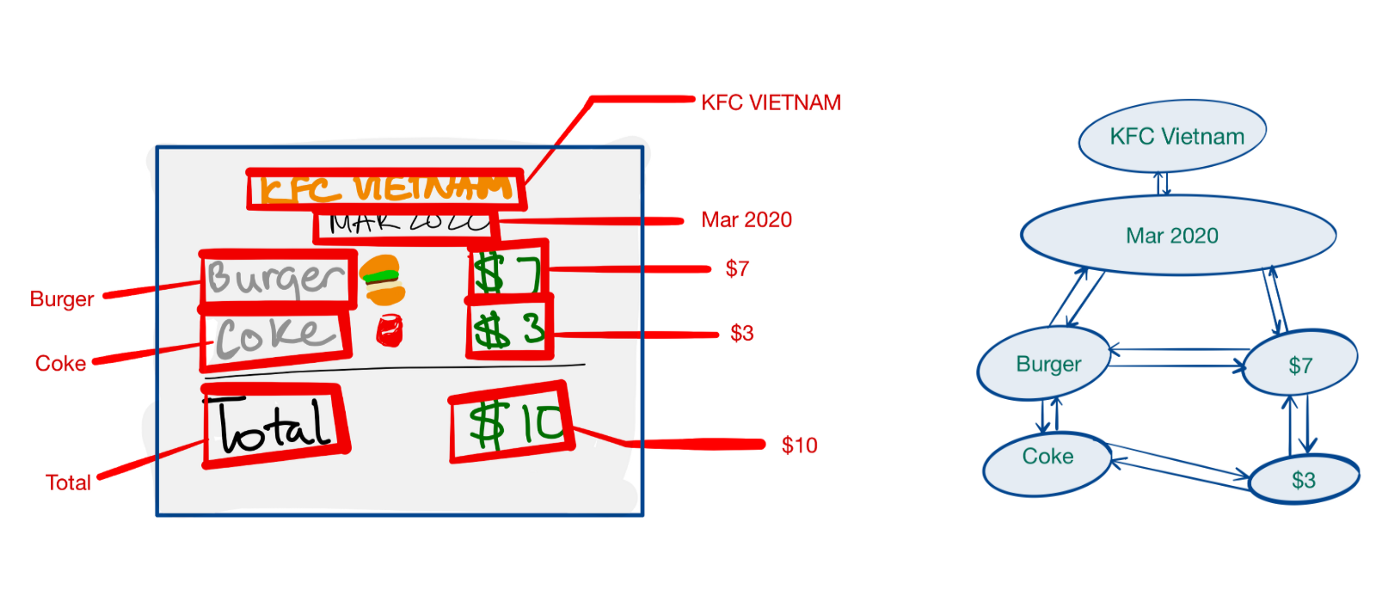
<Graphic representation of receipt>
By using graphs, you can:
By using Layout Detection and OCR output, it is possible to construct graphs with the following properties.
The class of each node is highly dependent on its neighbors.
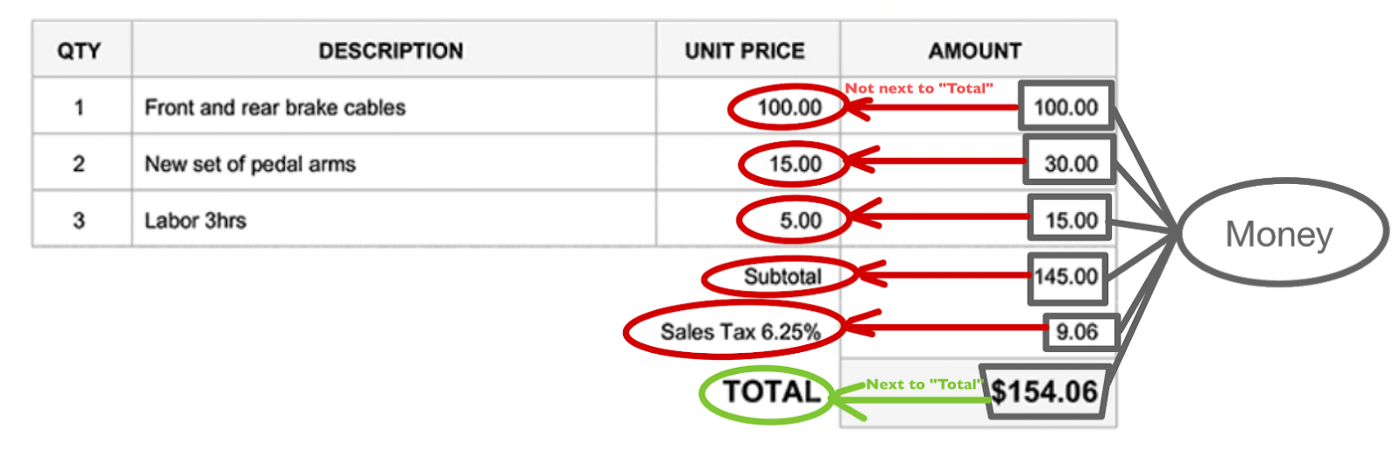
For example, if "$10" appears right next to "Total," it should represent the total amount of the receipt. On the other hand, if it's next to "cola" or "hamburger," it probably doesn't mean the total price.
This is an important point,location has important meaningabout it.
When classifying a node, all neighboring nodes must be considered. Since we wanted to include location in the decision when classifying nodes, our method decided to take all neighboring nodes into account when performing graph convolution.
The diagram below shows this.
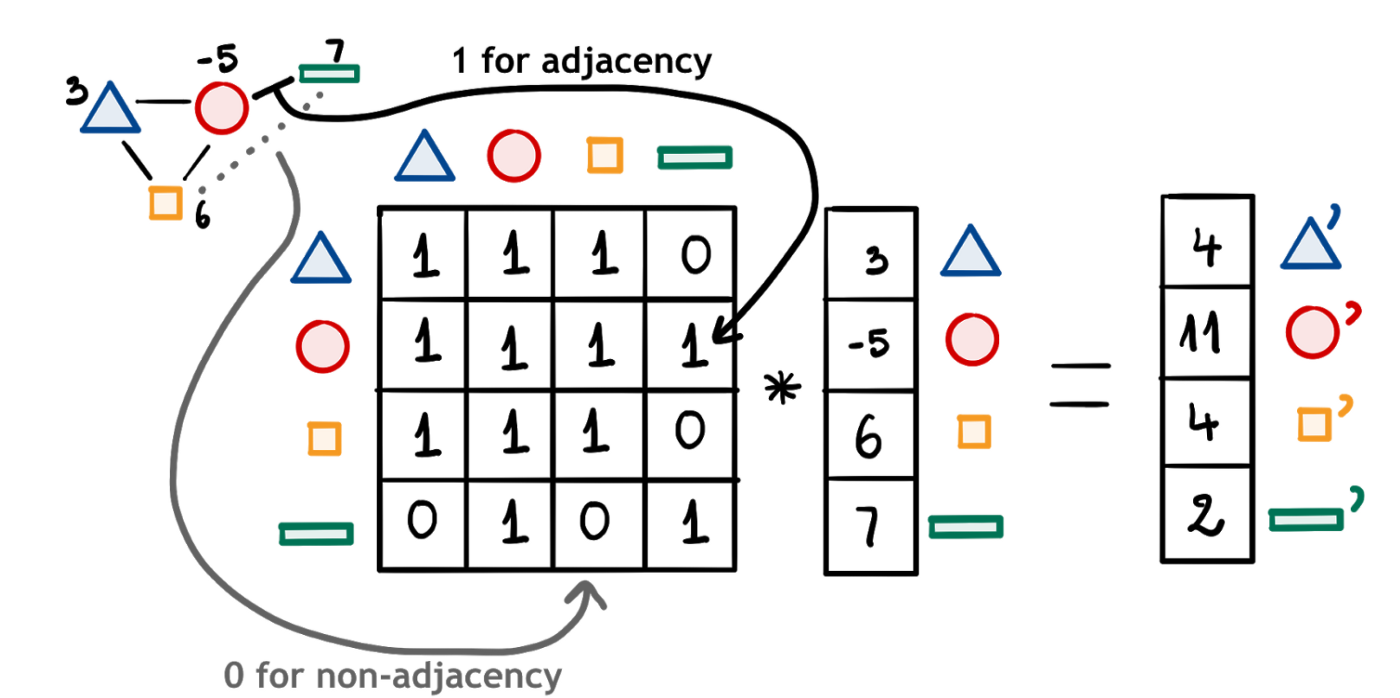
Graph convolution is being performed by matrix multiplication.
This is a mathematically and computationally convenient way to represent the convolution of a graph.
Shown below is a demo of key-value extraction using GCN. As I move the cursor over the various fields, I see the class that corresponds to that line of text (outlined in green) and all the adjacent nodes that explain the decision (outlined in red).We plan to introduce the "explainability" part of judgment in a separate article on key-value extraction.
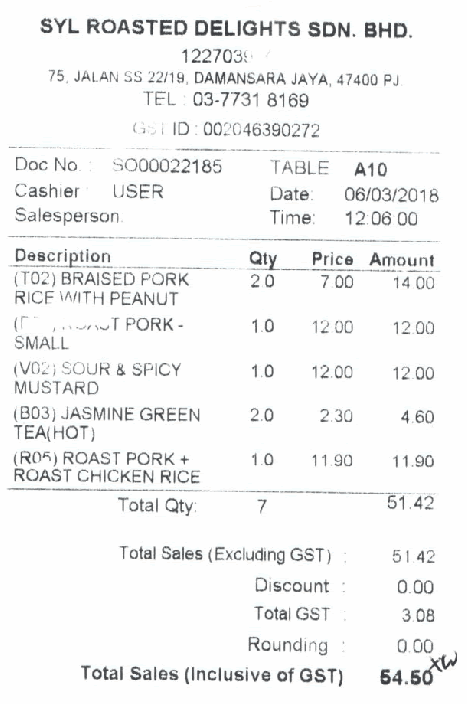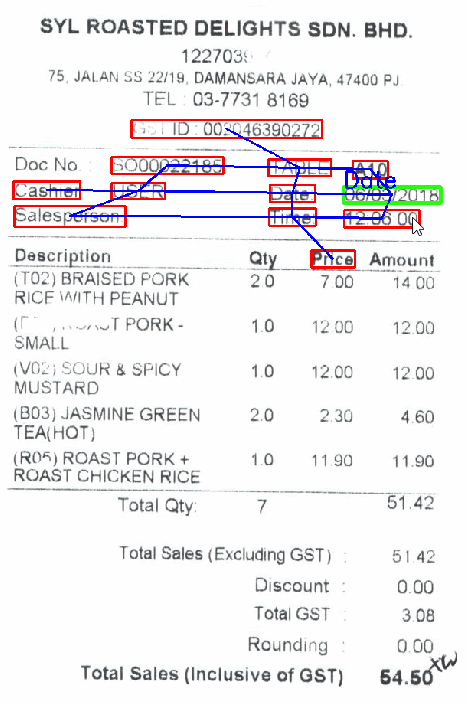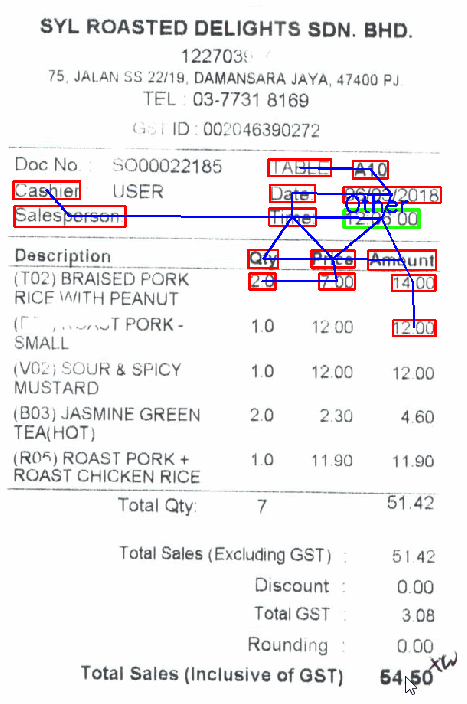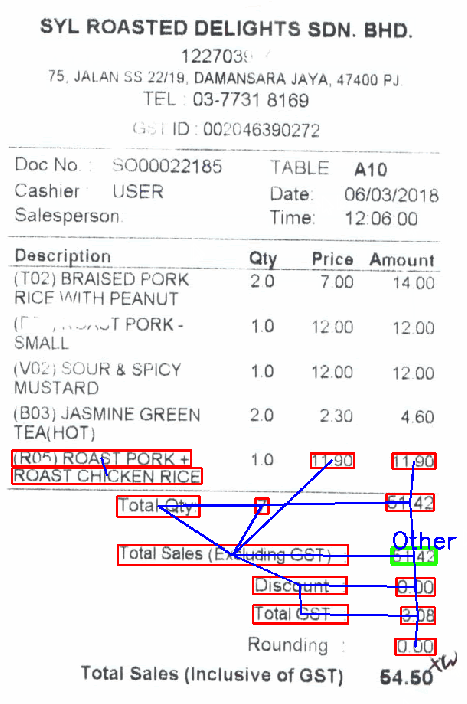
The most important point this time wasplaceis. The class of a text line is determined by its position within the receipt and the "meaning" of the text line itself. Therefore, by using a graph convolution network, we can effectively use the two pieces of information together.
Written by: Patrick
Consultant team: Marc, Sonny, Toni
For inquiries regarding this article or requests for business negotiations, please contactherePlease contact us from.
Also, Cinnamon AI regularlyHolding a seminarDoing.

